|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
2.3.8. СИНТАГМАТИЧЕСКАЯ ДЛИНА 2. Структура языка[24] 2.1. ВВОДНЫЕ ЗАМЕЧАНИЯ 2.1.1. «ЗВУКИ» И «СЛОВА» Если спросить нелингвиста, каковы элементарные единицы языка, кирпичики, из которых, так сказать, построены высказывания, он, вероятно, ответит, что элементарные единицы языка — это «звуки» и «слова». Возможно, он добавит, что слова состоят из последовательности звуков; каждый звук представлен, в идеальном случае, отдельной буквой алфавита (в языках, которые обычно пользуются алфавитной системой письма); и что слова языка обладают значением, тогда как звуки им не обладают (их единственная функция — участвовать в образовании слов). Эти немногие представления лежат в основе традиционного взгляда на язык, отраженного в большинстве грамматик и словарей: грамматика предлагает правила построения предложений из слов, а в словаре содержится информация о значениях отдельных слов. В последующих главах мы будем иметь возможность критически рассмотреть термины «звук», «слово», «значение» и «предложение», фигурирующие в этих общих утверждениях относительно языка. Однако для настоящего предварительного обсуждения структуры языка можно оставить эти термины без определения. Некоторые отличительные особенности будут упомянуты в настоящей главе и разъяснены позднее. 2.1.2. ФОНОЛОГИЯ, ГРАММАТИКА И СЕМАНТИКА Традиционный взгляд на язык включает понятия композиции (более сложная единица состоит из более простых, или меньших, единиц: слово состоит из звуков, словосочетание состоит из слов, простое предложение — из словосочетаний, сложное предложение — из простых предложений и т. д.) и корреляции (каждое слово соотносится с одним или более значений). Если использовать термин «уровень» для первого и термин «план» для второго понятия, то можно сказать, что в соответствии с моделью языковой структуры, условно принятой нами, каждый язык можно описать в терминах двух планов: «формы» и «значения», или лучше (так как этим традиционным терминам в лингвистике даются различные противоречивые толкования) — выражения и содержания. А план выражения языка можно описать на основе (по крайней мере) двух уровней: уровня звуков и уровня слов. Введем теперь термины, обычно используемые лингвистами: звуки какого-либо данного языка описываются фонологией; формы слов и способы их комбинации в словосочетаниях [25], простых и сложных предложениях — грамматикой; значение, или содержание, слов (и единиц, состоящих из них) — семантикой. 2.1.3. «ДВОЙНОЕ ЧЛЕНЕНИЕ» ЯЗЫКА * Лингвисты иногда говорят о «двойном членении» (или «двойной структуре») языка; и это сочетание часто ошибочно понимают как имеющее отношение к корреляции двух планов — плана выражения и плана содержания. Имеется же в виду то, что единицы «низшего» уровня — фонологии (звуки языка) — не имеют другой функции, кроме как, сочетаясь друг с другом, образовывать единицы «более высокого» уровня — грамматики (словa). Именно в силу двойной структуры плана выражения языки способны экономно представлять многие тысячи разных слов, поскольку каждое слово может быть представлено особым сочетанием из относительно небольшого набора звуков, точно так же, как каждое из бесконечно большого множества натуральных чисел обозначается в нормальной десятичной записи особым сочетанием из десяти основных цифр. 2.1.4. «УРОВЕНЬ» VERSUS «ПЛАН»,«ВЫРАЖЕНИЕ» VERSUS «СОДЕРЖАНИЕ» * Выделив два плана — выражения и содержания — и два уровня — фонологии и грамматики, — мы, конечно, ничуть не отошли от традиционного взгляда на структуру языка. Теперь мы должны посмотреть, что же именно характеризует более современный подход к изучению языка, обычно именуемый «структурной лингвистикой». 2.2. СУБСТАНЦИЯ И ФОРМА * 2.2.1. СТРУКТУРА СЛОВАРЯ Мало кто в наши дни будет отрицать, что соотношение определенного слова и определенного значения чисто условно. Длительный спор между «натуралистами» и «конвенционалистами» можно считать оконченным (ср. § 1.2.2). Но самый способ доказательства условности связи между «формой» и «значением» (между выражением и содержанием), а именно перечисление совершенно различных слов из разных языков, которые относятся к одной вещи или имеют одно и то же значение (например, tree 'дерево' в английском, Baum 'дерево' в немецком, arbre 'дерево' во французском языке), может поддерживать тот взгляд, согласно которому словарь любого языка представляет собой, в сущности, список имен, связанных по соглашению с существующими независимо от него предметами или значениями. Тем не менее, изучая иностранный язык, мы вскоре обнаруживаем, что один язык различает значения, которые не различаются в другом, и что выучить словарь другого языка — это не значит просто усвоить новый набор ярлыков, прилагаемых к уже известным значениям. Так, например, английское слово brother-in-law можно перевести на русский язык как 'зять' 'шурин', 'свояк' или 'деверь'; а одно из этих четырех русских слов, а именно слово зять, иногда следует переводить как son-in-law. Из этого нельзя, однако, заключить, что слово зять имеет два значения и что в одном из своих значений оно эквивалентно трем прочим. Все четыре слова в русском языке имеют различные значения. Оказывается, что русский язык объединяет (под словом 'зять') и мужа сестры, и мужа дочери, но различает брата жены ('шурин'), мужа сестры жены ('свояк') и брата мужа ('деверь'). Поэтому в русском языке, действительно, нет слова, означающего 'brother-in-law', точно так же,как в английском нет слова, означающего 'зять'. Каждый язык обладает своей собственной семантической структурой. Мы будем говорить, что два языка семантически изоморфны (то есть имеют одну и ту же семантическую структуру) в той мере, в какой значения одного языка могут быть поставлены в одно-однозначное соответствие со значениями другого. Степень семантического изоморфизма между различными языками неодинакова. Вообще (этот вопрос мы рассмотрим и поясним примерами более полно в главе, посвященной семантике; см. § 9.4.6) структура словаря отдельного языка отражает различия и сходства между предметами и понятиями, существенными для культуры общества, в котором действует этот язык. Следовательно, степень семантического изоморфизма между любыми двумя языками в значительной мере зависит от степени близости культуры двух обществ, использующих эти языки. Существуют ли или могут ли существовать два языка, словари которых вообще ни в какой степени не изоморфны один другому, — это вопрос, которым нам нет надобности заниматься. Мы будем считать по крайней мере возможным, что все значения, выделенные в некотором языке, присущи исключительно этому языку и не релевантны для других. 2.2.2. СУБСТАНЦИЯ И ФОРМА Ф. де Соссюр и его последователи объясняли различия в семантической структуре отдельных языков в терминах разграничения между субстанцией и формой. Под формой словаря (или формой плана содержания, ср. § 2.1.4) подразумевается абстрактная структура отношений, которую отдельный язык как бы накладывает на одну и ту же лежащую в основе субстанцию. Точно так же, как из одного и того же комка глины можно вылепить предметы различных очертаний и размеров, субстанция (или основа), в пределах которой устанавливаются различия и эквивалентности значений, может быть организована в разных языках в разные формы. Сам Ф. де Соссюр представлял себе субстанцию значения (субстанцию плана содержания) как нерасчлененную массу мыслей и эмоций, общих для всех людей, вне зависимости от языка, на котором они говорят, — как своего рода аморфную и недифференцированную концептуальную основу, из которой в отдельных языках в силу условного соединения некоторой совокупности звуков с некоторой частью концептуальной основы образуются значения. (Читателю следует обратить внимание на то, что в этом разделе термины «форма» и «субстанция» употребляются в значении, в каком они были введены в лингвистику и употреблялись Соссюром; см. § 4.1.5.) 2.2.3. СЕМАНТИЧЕСКАЯ СТРУКТУРА НА ПРИМЕРЕ ЦВЕТОВЫХ ОБОЗНАЧЕНИЙ В представлениях Соссюра о семантической структуре есть много такого, что можно отнести на счет устарелых психологических теорий и отвергнуть. Понятие концептуальной субстанции, не зависящей от языка и культуры, в целом обладает сомнительной ценностью. В действительности, многие философы, лингвисты и психологи нашего времени не склонны признавать, что значения можно удовлетворительно описать как идеи или понятия, существующие в сознании людей. Понятие субстанции, однако, можно проиллюстрировать, не прибегая к предположениям о существовании концептуальной основы. Установленным фактом является то, что цветовые обозначения в отдельных языках не всегда можно поставить в одно-однозначное соответствие друг с другом; например, английское слово brown 'коричневый' не имеет эквивалента во французском языке (оно переводится как brun, marron или даже jaune, в зависимости от конкретного оттенка, а также и вида определяемого им существительного); слово pila из языка хинди переводится на английский язык как yellow 'желтый', orange 'оранжевый' или даже brown 'коричневый' (хотя в хинди существуют разные слова для обозначения других оттенков коричневого цвета); в русском языке нет эквивалента для blue: слова 'голубой' и 'синий' (обычно переводимые так 'light blue' и 'dark blue' соответственно) относятся в русском языке к различным цветам, а не к разным оттенкам одного и того же цвета, как можно было бы предположить, исходя из их перевода на английский язык. Чтобы рассмотреть вопрос в возможно более общем виде, сравним фрагмент словарного запаса английского языка с фрагментом словарного запаса трех гипотетических языков — А, В и С. Для простоты ограничим наше внимание зоной спектра, покрываемой пятью обозначениями: red, orange, yellow, green, blue. 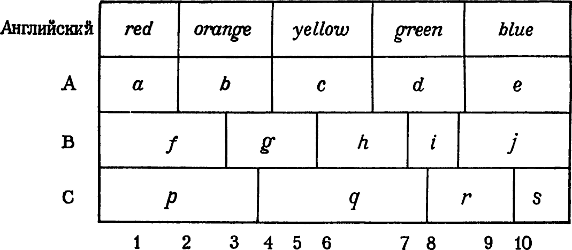 Рис. 1. Допустим, что одна и та же зона покрывается пятью словами в А: а, b, с, d и e, пятью словами в В: f, g, h, i и j и четырьмя словами в С: p, q, r и s (см. рис. 1). Из диаграммы ясно, что язык А семантически изоморфен английскому (в этой части словарного запаса): в нем то же количество цветовых обозначений, и границы между зонами спектра, покрываемыми каждым из них, совпадают с границами английских слов. Но ни В, ни С не изоморфны с английским языком. Так, В содержит то же количество цветовых обозначений, что и английский, но границы проходят в других местах спектра, а в С содержится иное число обозначений (и границы проходят в других местах). Чтобы оценить практические выводы из этого, представим себе, что у нас есть десять предметов (пронумерованных от 1 до 10 на рис. 1), каждый из которых отражает световые лучи разной длины волны, и что мы хотим сгруппировать их по цвету. В английском предмет 1 был бы охарактеризован как 'red', а предмет 2 — как 'orange'; следовательно, они бы различались по цвету; в языке А они бы также различались по цвету, поскольку описывались бы соответственно как а и b. Но в языках В и С они имели бы одно и то же цветовое обозначение — f или p. С другой стороны, предметы 2 и 3 различались бы в В (как f и g), но объединялись бы в английском и в А и в С (как 'orange', b и р). Из диаграммы ясно, что имеется множество случаев неэквивалентности такого рода. Конечно, мы не утверждаем, что носители языка В не видят никакой разницы в цвете между предметами 1 и 2. Они, вероятно, способны различать их примерно так же, как носители английского языка могут различать предметы 2 и 3, обозначая их, скажем, как reddish-orange 'красно-оранжевый' и yellow-orange 'желто-оранжевый'. Суть в том, что здесь мы имеем дело с иной первичной классификацией, а вторичная классификация основывается на первичной и предполагает ее существование (в рамках английской семантической структуры, например, crimson 'малиновый' и scarlet 'алый' обозначают «оттенки» одного и того же цвета red, тогда как русские слова голубой и синий, как мы видели, относятся к разным цветам первичной классификации). Субстанцию цветового словаря, следовательно, можно представлять себе как физический континуум, в пределах которого языки могут проводить одни и те же или различные разграничения, проходящие в одних и тех же или в различных местах. Было бы неразумным утверждать, что не существует чувственно воспринимаемых дискретных предметов и свойств мира, внешних по отношению к языку и не зависящих от него; что все находится в аморфном состоянии, пока ему не придаст форму язык. В то же время ясно, что способы объединения различных предметов, например флоры и фауны, в пределах отдельных слов могут меняться от языка к языку: латинское слово mus относится и к мыши и к крысе (так же, как и к некоторым другим грызунам); французское слово singe обозначает и человекообразных (apes) и прочих (monkeys) обезьян, и т. д. Чтобы факты такого рода ввести в сферу соссюровского объяснения семантической структуры, требуется более абстрактное понятие субстанции. Очевидно, невозможно описать словарь терминов родства с точки зрения наложения формы на лежащую в ее основе физическую субстанцию. Только ограниченное число слов может быть описано, исходя из отношений между близкими явлениями в пределах физического континуума. И мы увидим ниже, что даже словарь названий цветовых обозначений (который часто приводится в качестве одного из самых ясных примеров того, что имеется в виду под наложением формы на субстанцию плана содержания) более сложен, чем обычно предполагают (см. § 9.4.5). Дополнительные сложности, впрочем, не затрагивают сущности вопросов, которых мы коснулись в этом разделе. Достаточно того, что по крайней мере для некоторых фрагментов словаря можно допустить существование исходной субстанции содержания. Однако понятие семантической структуры не зависит от этого предположения. В качестве самого общего утверждения относительно семантической структуры — утверждения, применимого ко всем словам, независимо от того, относятся они к предметам и свойствам физического мира или нет, — мы можем принять следующую формулировку: семантическая структура любой системы слов в словаре есть сеть семантических отношений, наличествующих между словами данной системы. Рассмотрение вопроса о природе этих отношений отложим до главы, посвященной семантике. Пока же важно отметить, что данное определение использует в качестве ключевых термины система и отношение. Цветовые обозначения (как и термины родства и многие другие классы слов различных языков) представляют собой упорядоченную систему слов, находящихся в определенных отношениях друг с другом. Такие системы изоморфны, если они содержат одно и то же число единиц и если эти единицы находятся в одинаковых отношениях друг с другом. 2.2.4. «ЯЗЫК ЕСТЬ ФОРМА, А НЕ СУБСТАНЦИЯ» Прежде чем обсуждать противопоставление субстанции и формы в отношении плана выражения (где оно в действительности обладает большей общностью), полезно вернуться к аналогии с шахматной игрой, предложенной Ф. де Соссюром. Прежде всего можно отметить, что материал, из которого сделаны шахматные фигуры, не релевантен для процесса игры. Шахматы можно сделать вообще из любого материала (дерева, слоновой кости, пластмассы и т. д.), если только физическая природа материала способна сохранять значимые различия между очертаниями фигур в условиях нормальной шахматной игры. (Этот последний момент — физическая устойчивость материала, — очевидно, важен; Ф.де Соссюр не подчеркивал этого, а считал само собой разумеющимся. Шахматные фигуры, вырезанные, например, изо льда, не годились бы, если бы игра проходила в теплой комнате.) Нерелевантен не только материал, из которого сделаны фигуры, но также детали их очертаний. Необходимо только, чтобы каждая из них опознавалась бы как фигура, которая ходит определенным образом по правилам игры. Если мы потеряем или сломаем одну из фигур, мы сможем заменить ее каким-нибудь другим предметом (монетой или куском мела, например) и заключить соглашение о том, что будем рассматривать новый предмет в игре как фигуру, которую он заменяет. Связь между очертаниями фигуры и ее функцией в игре — это вопрос произвольного соглашения. При условии, что эти соглашения приняты партнерами, можно играть с одинаковым успехом фигурами любых очертаний. Если сделать выводы из этой аналогии в отношении плана выражения языка, то мы ближе подойдем к пониманию одного из основных принципов современной лингвистики: говоря словами Соссюра, язык есть форма, а не субстанция. 2.2.5. «РЕАЛИЗАЦИЯ» В СУБСТАНЦИИ Как мы видели в предыдущей главе, устная речь предваряет письмо (см. § 1.4.2). Другими словами, первичная субстанция языкового плана выражения — звуки (а именно, диапазон звуков, производимых человеческими органами речи); письмо же представляет собой, в сущности, способ перенесения слов и предложений некоторого языка из субстанции, в которой они нормально реализуются, во вторичную субстанцию начертаний (видимые значки на бумаге или камне и т. п.). Возможен дальнейший перенос — из вторичной в третичную субстанцию, как, например, при передаче сообщений по телеграфу. Сама возможность осуществления такого переноса (его можно было бы назвать «транссубстанциацией») свидетельствует о том, что структура языкового плана выражения оказывается в весьма значительной степени независимой от субстанции, в которой она реализуется. Для простоты рассмотрим сначала языки, использующие алфавитную систему письма. Допустим, что звуки языка находятся в одно-однозначном соответствии с буквами алфавита, используемыми для их представления (другими словами, что каждый звук представлен особой буквой и каждая буква всегда обозначает один и тот же звук). Если это условие будет выполнено, не будет ни омографии, ни омофонии — будет одно-однозначное соответствие между словами письменного языка и словами устного языка, и (исходя из упрощенного предположения, что предложения состоят только из слов) все предложения письменного и устного языка будут также находиться в одно-однозначном соответствии. Поэтому письменный и устный языки будут изоморфны. (То, что, как мы уже видели, письменный и устный языки никогда не бывают совершенно изоморфны, здесь не имеет значения. В той степени, в какой они не изоморфны, — это разные языки. Это одно из следствий того принципа, что язык есть форма, а не субстанция.) Чтобы предотвратить недоразумение, мы будем пользоваться квадратными скобками для отличия звуков от букв (это стандартное условное обозначение; ср. § 3.1.3). Так, [t], [е] и т.д. будут обозначать звуки, a t, е и т. д. будут обозначать буквы. Теперь мы можем ввести различие между формальными единицами и их субстанциальной реализацией посредством звуков и букв. Когда мы говорим, что [t] находится в соответствии с t, [е] — с е, и вообще, когда мы говорим, что определенный звук находится в соответствии с определенной буквой и vice versa, мы можем истолковать это утверждение в том смысле, что ни звуки, ни буквы не являются первичными, но и те и другие суть альтернативные реализации одних и тех же формальных единиц, которые сами по себе являются совершенно абстрактными элементами, независимыми от субстанции, в которой они реализуются. Для целей, преследуемых в настоящем разделе, назовем эти формальные единицы «элементами выражения». Используя для их обозначения цифры (и заключая их в косые скобки), мы можем сказать, что /1/ обозначает определенный элемент выражения, который может реализоваться в звуковой субстанции звуком [t] и в графической субстанции буквой t; что /2/обозначает другой элемент выражения, который может реализоваться как [е] и е, и так далее. Теперь ясно, что точно так же, как шахматные фигуры могут быть сделаны из различных сортов материала, один и тот же набор элементов выражения может быть реализован не только при помощи звуков и начертаний, но и во многих других видах субстанции. Например, каждый элемент мог бы реализоваться светом того или иного цвета, определенными жестами, посредством определенного запаха, бoльшим или меньшим пожатием руки и т. д. Можно даже, очевидно, построить коммуникативную систему, в которой разные элементы были бы реализованы различными видами субстанции — систему, в которой, например, элемент /1/ реализовался бы звуком (любого рода), /2/ — светом (любого цвета), /3/ — жестом руки и т. д. Однако мы не будем учитывать эту возможность и лучше сосредоточим свое внимание на способах реализации элементов выражения посредством различий в некоторой однородной субстанции. Это более типично для человеческого языка. Хотя устная речь может сопровождаться различными конвенциональными жестами и тем или иным выражением лица, эти жесты и мимика не реализуют формальных единиц того же уровня, что и единицы, реализуемые звуками, входящими в состав сопутствующих жестам слов; иначе говоря, определенный жест, сочетаясь со звуками, не образует слова, как это имеет место при сочетании двух или более звуков, образующих слово. В принципе элементы выражения языка могут быть реализованы в субстанции любого рода, если только будут удовлетворяться следующие условия: (а) отправитель «сообщения» должен иметь в своем распоряжении необходимый аппарат для того, чтобы производить значимые различия в субстанции (различия звуков, начертаний и т. д.), а получатель сообщения должен иметь аппарат, необходимый для того, чтобы воспринимать эти различия; другими словами, отправитель (говорящий, пишущий и т. д.) должен иметь необходимый «кодирующий» аппарат, а получатель (слушающий, читающий и т. д.) должен иметь соответствующий «декодирующий» аппарат; (b) сама субстанция как среда, в которой устанавливаются эти различия, должна быть достаточно устойчивой, чтобы сохранять различия в реализации элементов выражения в течение того времени, которое при нормальных условиях коммуникации необходимо для передачи сообщений от отправителя к получателю. 2.2.6. СУБСТАНЦИЯ УСТНОГО И ПИСЬМЕННОГО ЯЗЫКА Ни одно ни другое из этих условий не требует подробных комментариев. Тем не менее краткое сравнение речи и письма (точнее, звуковой и графической субстанции) может быть полезно с точки зрения выяснения: (а) их доступности и удобства и (b) их физической устойчивости или прочности. В своих размышлениях о происхождении языка многие лингвисты приходили к заключению, что звуки — это наиболее подходящий материал развития языка по сравнению со всеми другими возможными средствами. В противоположность жестам или любой другой субстанции, в пределах которой различия воспринимаются посредством зрения (весьма развитого чувства у человеческих существ), звуковая волна не зависит от наличия источника света, и ей обычно не препятствуют предметы, лежащие на пути ее распространения: она в равной мере подходит для коммуникации как днем, так и ночью. В отличие от разных видов субстанции, в пределах которой необходимые различия производятся и воспринимаются при помощи осязания, звуковая субстанция не требует, чтобы отправитель и получатель находились в непосредственной близости; она оставляет руки свободными для деятельности другого рода. Какие бы другие факторы ни могли влиять на развитие человеческой речи, ясно, что звуковая субстанция (тот диапазон звуков, который соответствует нормальным произносительным и слуховым возможностям человека) удовлетворяет условиям доступности и удобства достаточно хорошо. Только относительно небольшое число людей физически не способно производить или воспринимать различия в звуках. Если иметь в виду те формы общения, которые, как можно предполагать, были наиболее естественными и необходимыми в первобытных обществах, то можно считать звуковую субстанцию достаточно удовлетворительной и в отношении физической устойчивости сигналов. Графическая субстанция до некоторой степени отличается от звуковой субстанции с точки зрения удобства и доступности: она требует применения того или иного орудия и не оставляет руки свободными для выполнения каких-либо сопутствующих коммуникации действий. Значительно более важным, однако, является то, что они отличаются друг от друга по долговечности. Вплоть до относительно недавнего времени (до изобретения телефона и звукозаписывающей аппаратуры) звуковую субстанцию нельзя было использовать как вполне надежное средство коммуникации, если отправитель и получатель не присутствовали в одном и том же месте в одно и то же время. (Носители устных преданий и посыльные, к которым обращались для передачи того или иного сообщения, должны были полагаться на память.) Звуки сами по себе как бы затухали и, если не были немедленно «декодированы», утрачивались навсегда. Но с изобретением письма для «кодирования» языка было найдено другое, более долговечное средство. Хотя письмо было менее удобно (и поэтому неупотребительно) для более кратковременной коммуникации, оно делало возможным передачу сообщений на значительные расстояния, а также их хранение для будущего. Различия в условиях наиболее типичного употребления, которые существовали и все еще существуют между речью и письмом (речь представляет собой непосредственное личное общение; письмо — это более тщательно составленные тексты, предназначенные для чтения и понимания без помощи «ключей», предоставляемых непосредственной ситуацией), много дают как для объяснения происхождения письма, так и для объяснения многих последующих расхождений между письменной и устной речью. Как мы уже видели, эти различия таковы, что было бы неточно сказать, что для языков, имеющих длительную традицию письменности, письмо — это только перенесение речи в другую субстанцию (см. § 1.4.2). При всех различиях в физической устойчивости звуковой и графической субстанций, несомненно существенных в историческом развитии письменного и устного языка, бесспорным является, что оба вида субстанции достаточно устойчивы для сохранения перцептуальных различий между звуками или начертаниями, реализующими элементы выражения, в условиях, в которых обычно используются устная речь и письмо. 2.2.7. ПРОИЗВОЛЬНОСТЬ СУБСТАНЦИАЛЬНОЙ РЕАЛИЗАЦИИ * Мы можем теперь обратиться ко второму утверждению Соссюра относительно субстанции, в которой реализуется язык: точно так же, как очертания шахматных фигур не релевантны для процесса игры, не существенны и те конкретные особенности начертаний или звуков, посредством которых идентифицируются элементы выражения языка. Другими словами, связь отдельного звука или буквы с определенным элементом выражения есть дело произвольного соглашения. Это можно пояснить на примере из английского языка. В таблице 3 даются в колонке (i) шесть элементов выражения английского языка, произвольно пронумерованные от 1 до 6; в колонке (ii) даются их нормальные орфографические представления, а в колонке (iii) — их реализация в качестве звуков. (Для простоты допустим, что звуки [t], [е] и т. д. далее неразложимы и реализуют минимальные элементы выражения языка, как они обнаруживаются, например, в словах, записанных в виде Таблица 3 Элементы выражения
Слова
bet, pet, bid и т. д. Хотя это предположение будет подвергнуто сомнению в следующей главе, модификации, которые мы сочтем необходимым сделать, не повлияют на наше рассуждение.) Теперь примем другое произвольное условие, согласно которому /1/ реализуется орфографически как р, /2/ — как i и т. д.; см. колонку (iv). В результате слово А (которое означает 'пари' и прежде писалось bet) будет теперь записываться как dip, слово В будет писаться как tip и т. д.; см. колонки (vii), (viii) и (ix). Совершенно ясно, что каждые два слова или предложения письменного английского языка, различавшиеся в принятой орфографии, также различаются и в нашей новой условной орфографии. Сам язык остается совершенно не затронутым изменениями, касающимися его субстанциальной реализации. То же применимо и к устному языку (но с некоторыми ограничениями, которые мы ниже введем). Предположим, что элемент выражения /1/ реализуется в звуковой субстанции как [р], /2/ — как [i] и т. д. — см. колонку (v). Тогда слово, которое сейчас пишется bet (и может продолжать писаться bet, поскольку, очевидно, между звуками и буквами нет внутренней связи), будет произноситься как слово, которое сейчас пишется dip (хотя значение его останется все тем же 'bet' 'пари'); и так для всех прочих слов; см. колонку (х). Снова мы обнаруживаем, что при изменениях субстанциальной реализации сам язык не изменяется. 2.2.8. ПЕРВИЧНОСТЬ ЗВУКОВОЙ СУБСТАНЦИИ Однако все же имеется важное различие между графической и звуковой реализацией языка; и именно это различие вынуждает нас видоизменить строгий соссюровский принцип, согласно которому элементы выражения совершенно не зависят от субстанции, в которой они реализуются. Тогда как в начертании букв d, b, е и т. д. нет ничего, что запрещало бы нам комбинировать их любым способом, который мог бы прийти нам в голову, некоторые сочетания звуков оказываются непроизносимыми. Например, мы могли бы решить принять для письменного языка набор реализаций, перечисленных в колонке (vi) нашей таблицы, так, чтобы слово А писалось dbe, слово В — ibe и т. д. — см. колонку (xi). Последовательности букв из колонки (хi) могут быть написаны или напечатаны с такой же легкостью, как и последовательности из колонки (iх). Напротив, те звуковые комплексы, которые получились бы вследствие замены [b] на [d], [i] на [t] и [d] на [р] в слове 'bid' (слово Е), были бы неудобопроизносимыми. Тот факт, что на произносимость (и внятность) определенных групп или комплексов звуков накладываются некоторые ограничения, означает, что элементы выражения языка, или, скорее, их комбинации, частично определяются природой их первичной субстанции и «механизмов» речи и слуха. В диапазоне возможностей, ограниченном требованием произносимости (и внятности), каждый язык имеет собственные комбинаторные ограничения, которые можно отнести на счет фонологической структуры рассматриваемого языка. Поскольку мы еще не провели грани между фонетикой и фонологией (см. гл. 3), мы должны здесь удовольствоваться несколько неточным изложением данного вопроса. Мы примем без доказательств подразделение звуков на согласные и гласные и допустим, что эта классификация является обоснованной как в общей фонетической теории, так и в описании комбинаторных возможностей отдельных языков, включая английский. Итак, замена [t] на [р], [i] на [е] и т. д. (см. колонку (iv)) не оказывает существенного влияния на произношение потому (между прочим), что при этой замене звуки сохраняют свой первоначальный консонантный либо вокалический характер. Это не только гарантирует произносимость получающихся в результате слов, но также не нарушает нормальную для них (как для слов английского языка) фонологическую структуру, которая характеризуется определенным соотношением согласных и гласных и определенным способом сочетания звуков этих двух классов. Однако мы должны понимать, что можно произвести другие подобные замены, которые, хотя и будут удовлетворять условию произносимости, но изменят соотношение согласных и гласных и модели их сочетания в словах. Тем не менее при условии, что все слова устного английского языка останутся различными при новой системе реализации элементов выражения, грамматическая струк тура языка не изменится. Следует поэтому в принципе допустить, что два (или более) языка могут быть грамматически, но не фонологически, изоморфными. Языки изоморфны фонологически тогда, и только тогда, когда звуки одного языка находятся в одно-однозначном соответствии со звуками другого языка и соответствующие классы звуков (например, согласные и гласные) подчиняются одним и тем же законам сочетаемости. Одно-однозначное соответствие между звуками не предполагает их тождества. С другой стороны, как мы видели, законы сочетаемости не являются целиком независимыми от физической природы звуков. Вывод из предыдущих двух абзацев подтверждает обоснованность тех представлений, согласно которым общая лингвистическая теория признает приоритет устного языка перед письменным (ср. § 1.4.2). Законы сочетаемости, которым подчиняются буквы в письменном языке, совершенно необъяснимы на основе начертаний букв, тогда как они, по крайней мере частично, определяются физической природой звуков в соответствующих произносимых словах. Например, u и n соотносятся друг с другом по начертанию точно так же, как d и p. Но этот факт не имеет ровно никакого отношения к тому, как эти буквы сочетаются друг с другом в написанных английских словах. Значительно более релевантен тот факт, что рассматриваемые буквы находятся в частичном соответствии со звуками устного языка. Изучение звуковой субстанции представляет для лингвиста гораздо больший интерес, чем исследование графической субстанции и систем письма. 2.2.9. КОМБИНАЦИЯ И КОНТРАСТ Единственными свойствами, которыми обладают элементы выражения, рассматриваемые в отвлечении от их субстанциальной реализации, являются (i) их комбинаторная функция — их способность сочетаться друг с другом в группах или комплексах, служащих для отождествления и различения слов и предложений (как мы только что видели, комбинаторные способности элементов выражения в действительности частично определяются природой их первичной, то есть звуковой, субстанции), и (ii) их контрастивная функция — их отличие друг от друга. Именно второе из этих свойств имел в виду Ф. де Соссюр, когда он говорил, что элементы выражения (и, обобщая, все лингвистические единицы) по своей природе негативны: принцип контраста (или оппозиции) является фундаментальным принципом современной лингвистической теории. Это можно проиллюстрировать материалом табл. 3 на стр. 80. Каждый из элементов выражения (пронумерованных в таблице от 1 до 6) контрастирует, или находится в оппозиции, с каждым другим элементом, который может встретиться в той же позиции в английских словах, в том смысле, что замена одного элемента другим (точнее, замена субстанциальной реализации одного элемента субстанциальной реализацией другого) приводит к превращению одного слова в другое. Например, слово A (bet) отличается от слова В (pet) тем, что оно начинается с /3/, а не с /6/; от слова С (bit) А отличается тем, что в нем в середине представлено /2/, а не /5/, и от слова F (bed) оно отличается тем, что оно оканчивается на /1/, а не на /4/. Исходя из этих шести слов, мы можем сказать, что /1/ контрастирует с /4/, /2/ — с /5/ и /3/ — с /6/. (Взяв для сравнения другие слова, мы, конечно, смогли бы установить другие противопоставления и другие элементы выражения.) В качестве формальной единицы и в пределах рассматриваемого класса единиц /1/ можно определить как элемент, не совпадающий с /4/ и сочетающийся с /2/ или /5/ и с /3/ или /6/; аналогичным образом можно определить все другие элементы в таблице. Вообще, любая формальная единица может быть определена (i) как отличная от всех прочих элементов, противопоставленных ей, и (ii) как имеющая определенные комбинаторные свойства. 2.2.10. ДИСКРЕТНОСТЬ ЭЛЕМЕНТОВ ВЫРАЖЕНИЯ Теперь, исходя из различия между формой и субстанцией, можно ввести некоторые важные положения. Рассмотрим в качестве примера контрастность между /3/ и /6/, сохраняемую в устном языке благодаря различию между звуками [b] и [р|. Как мы видели, тот факт, что мы имеем дело именно с данным различием звуков, а не с каким-либо другим, не релевантен для структуры английского языка. Следует также заметить, что различие между [b] и [р] не абсолютно, но относительно. Иными словами, то, что мы называем «звук [b]» или «звук [р]», представляет собой ряд звуков, и в действительности нет определенной точки, где начинается «ряд [b]» и заканчивается «ряд [р]» (или vice versa). С фонетической точки зрения, различие между [b] и [р] носит градуальный характер. Но различие между элементами выражения /3/ и /6/ является абсолютным в следующем смысле. Слова А и В (bet и pet) и все остальные английские слова, различающиеся наличием /3/ или /6/, не переходят постепенно одно в другое в устном языке, подобно тому как [b] преобразуется постепенно в [р]. Может существовать какая-то точка, где невозможно отличить А или В имеется в виду, но в английском нет слова, которое идентифицировалось бы с помощью звука, промежуточного между [b] и [р], и соответственно занимало бы промежуточное положение между А и В в отношении грамматической функции или значения. Из этого следует, что план выражения языка построен из дискретных единиц. Но эти дискретные единицы реализуются в физической субстанции рядами звуков, внутри которых возможны значительные колебания. Поскольку единицы выражения не должны смешиваться одна с другой в своей субстанциальной реализации, должен существовать некоторый «запас прочности», обеспечивающий отличимость ряда звуков, реализующего одну из них, от ряда звуков, реализующего другую. Некоторые контрасты могут быть утрачены с течением времени либо могут не удержаться во всех словах у всех носителей языка. Этот факт можно объяснить, по-видимому, тем, что такие контрасты находятся за пределами нижнего «порога» важности, определяемого количеством различаемых посредством этих контрастов высказываний. Было бы, однако, ошибочным полагать, что различие между теми или иными элементами выражения является относительным, а не абсолютным. 2.2.11. ГРАММАТИЧЕСКИЕ И ФОНОЛОГИЧЕСКИЕ СЛОВА Теперь мы в состоянии устранить двусмысленность термина «композиция», как он употреблялся в предыдущем разделе. Было сказано, что слова состоят из звуков (или букв) и что предложения и словосочетания состоят из слов (см. § 2.1.1). Должно быть, однако, очевидным, что термин «слово» является неоднозначным. На самом деле он обычно используется в нескольких различных значениях, но здесь нам будет достаточно выделить только два. В качестве формальных, грамматических единиц слова можно рассматривать как полностью абстрактные сущности, единственными свойствами которых являются контрастивная и комбинаторная функции (позже мы рассмотрим вопрос о том, чтo значат контраст и комбинация в применении к грамматическим единицам). Но эти грамматические слова реализуются группами или комплексами элементов выражения, каждый из которых (в устном языке) реализуется отдельным звуком. Мы можем назвать комплексы элементов выражения фонологическими словами. Необходимость такого разграничения (мы вернемся к нему ниже: см. § 5.4.3) очевидна из следующих соображений. Прежде всего, внутренняя структура фонологического слова вообще не имеет отношения к тому факту, что оно реализует определенное грамматическое слово. Например, грамматическое слово А (которое означает «пари» — см. табл. 3, стр. 81) оказывается реализуемым при помощи комплекса элементов выражения /3 2 1/; но оно могло бы в равной мере реализоваться комплексом других элементов выражения и не обязательно в количестве трех. (Заметим, что это не то же самое, на что мы указали ранее, касаясь реализации элементов выражения. Фонологическое слово состоит не из звуков, а из элементов выражения.) Кроме того, грамматические и фонологические слова языка не обязательно находятся в одно-однозначном соответствии. Например, фонологическое слово, обозначаемое в нормальном орфографическом представлении как down, реализует по крайней мере два грамматических слова (ср. down the hill 'вниз с холма', the soft down on his cheek 'мягкий пушок на его щеке'), и это — различные грамматические слова, потому что им присущи различные контрастивные и комбинаторные функции в предложениях. Пример противоположного явления представляют альтернативные реализации одного и того же грамматического слова (прошедшее время определенного глагола), которые можно записать как dreamed и dreamt. Можно отметить, между прочим, что указанные два явления обычно трактуются как виды омонимии и синонимии (см. § 1.2.3). Выше мы не обращались к значению слов, а учитывали только их грамматическую функцию и фонологическую реализацию. Итак, резюмируем сказанное выше: грамматические слова реализуются фонологическими словами (причем между ними не предполагается одно-однозначное соответствие), а фонологические слова состоят из элементов выражения. Очевидно, термину «слово» можно придать еще третье значение, согласно которому мы могли бы утверждать, что английское слово cap и французское слово cap идентичны: они одинаковы в (графической) субстанции. Но в лингвистике мы не занимаемся субстанциальной тождественностью слов. Между грамматическим словом и его субстанциальной реализацией в звуках или начертаниях связь косвенная в том смысле, что она устанавливается посредством промежуточного фонологического уровня. 2.2.12. «АБСТРАКТНОСТЬ» ЛИНГВИСТИЧЕСКОЙ ТЕОРИЙ Может показаться, что рассуждения в этом разделе далеки от практических соображений. Это не так. Именно достаточно отвлеченный подход к изучению языка, опирающийся на разграничение между субстанцией и формой, обусловил более глубокое понимание исторического развития языков, чем это было возможно в XIX в., и привел позднее к построению более исчерпывающих теорий относительно структуры человеческого языка, его усвоения и использования. И такие теории были приложены к сугубо практическим целям: в разработке более эффективных способов обучения языкам, в построении лучших систем телекоммуникации, в криптографии и в конструировании систем для анализа языков посредством компьютера. В лингвистике, как и в других науках, абстрактная теория и ее практическое применение идут рука об руку; однако теория предшествует практическому применению и оценивается независимо, способствуя более глубокому пониманию предмета своего исследования. 2.3. ПАРАДИГМАТИЧЕСКИЕ И СИНТАГМАТИЧЕСКИЕ ОТНОШЕНИЯ * 2.3.1. ПОНЯТИЕ ДИСТРИБУЦИИ На каждую языковую единицу (за исключением предложения; см. § 5.2.1) в большей или меньшей степени накладываются ограничения в отношении контекстов, в которых она может употребляться. Этот факт отражается в утверждении, что каждая лингвистическая единица (ниже уровня предложения) имеет специфическую дистрибуцию. Если две (или более) единицы встречаются в одном и том же множестве контекстов, то говорят, что они эквивалентны по дистрибуции (или имеют одинаковое распределение); если у них нет общих контекстов, то они находятся в дополнительной дистрибуции. Между двумя крайностями — полной эквивалентностью и дополнительной дистрибуцией — нам следует выделить два типа частичной эквивалентности: (а) дистрибуция одной единицы может включать дистрибуцию другой (не будучи полностью эквивалентной ей): если х встречается во всех контекстах, в которых встречается у, но существуют контексты, в которых встречается у, но не встречается х, то дистрибуция у включает дистрибуцию х; (b) дистрибуции двух (или более) единиц могут частично совпадать (или пересекаться): если существуют контексты, в которых встречаются как х, так и у, но ни одна из них не встречается во всех контекстах, в которых встречается другая, тогда говорят, что х и у имеют частично совпадающую дистрибуцию. (Тем читателям, которые знакомы с некоторыми основными понятиями формальной логики и математики, будет ясно, что различные виды дистрибутивных связей между языковыми единицами можно описать в рамках логики классов и теории множеств. Этот факт весьма существен при изучении логических оснований лингвистической теории. То, что можно было бы назвать в широком смысле «математической» лингвистикой, теперь представляет собой очень важную часть нашей науки [26]. В настоящем вводном изложении основ лингвистической теории мы не можем подробно рассматривать различные отрасли «математической лингвистики», однако по мере необходимости мы будем обращаться к некоторым наиболее важным точкам соприкосновения с нею.  Рис. 2. Дистрибутивные отношения (х появляется во множестве контекстов А, а В — это множество контекстов, в которых встречается у). Следует подчеркнуть, что термин «дистрибуция» относится к множеству контекстов, в которых встречается лингвистическая единица, но лишь в той мере, в какой ограничения, накладываемые на появление рассматриваемой единицы в том или ином контексте, поддаются систематизации. Что здесь подразумевается под «систематизацией», объясним на конкретном примере. Элементы /l/ и /r/ имеют в английском языке, по крайней мере частично, эквивалентную дистрибуцию (об употреблении нами косых скобок см. 2.2.5): и тот и другой встречаются в ряде в остальном фонологически тождественных слов (ср. light 'свет': right 'правый', lamb 'ягненок': ram 'баран', blaze 'пламя': braise 'тушить', climb 'лазить': crime 'преступление' и т. д.). Но многим словам, в которых встречается один элемент, нельзя поставить в соответствие в остальном фонологически тождественные слова, в которых бы встречался другой элемент: не существует слова srip в качестве пары для slip 'скользить', слова tlip в качестве пары для trip 'поездка', не существует слова brend при существовании blend 'смесь', нет слова blick как пары для brick 'кирпич' и т. д. Однако имеется существенное отличие между отсутствием таких слов, как srip и tlip, с одной стороны, и таких, как brend и blick, — с другой. Первые два (и подобные им слова) исключаются в силу определенных общих законов, которым подчиняется фонологическая структура английских слов: в английском нет слов, начинающихся с /tl/ или /sr/ (данное утверждение можно сформулировать в более общих терминах, но для настоящих целей вполне достаточно сформулированного нами правила в том виде, в каком мы его только что изложили). Напротив, нельзя сделать никакого системного утверждения о дистрибуции /l/ и /r/, которое объяснило бы отсутствие слов blick и brend. Оба элемента появляются в других словах в окружении /b-i. . ./ и /b-е. . ./; ср. blink 'мигать': brink 'грань', blessed 'благословенный': breast 'грудь' и т. д. С точки зрения своей фонологической структуры brend и blick (но не tlip и srip) — вполне приемлемые слова для английского языка. Чистая «случайность», так сказать, что им не приданы грамматическая функция и значение, и они не используются языком. То, что мы сейчас проиллюстрировали посредством фонологического примера, приложимо также и к грамматическому уровню. Не все сочетания слов приемлемы. Из неприемлемых сочетаний часть объясняется в терминах общей дистрибутивной классификации слов языка, тогда как остальные приходится объяснять, обращаясь к значению конкретных слов или к каким-либо другим их индивидуальным свойствам. Мы вернемся к этому вопросу позднее (см. § 4.2.9). Для целей настоящего рассуждения достаточно отметить, что эквивалентная дистрибуция, полная или частичная, не предполагает абсолютной тождественности окружений, в которых встречаются рассматриваемые единицы: она предполагает тождественность постольку, поскольку эти окружения определяются фонологическими и грамматическими правилами языка. 2.3.2. СВОБОДНОЕ ВАРЬИРОВАНИЕ Как мы видели в предыдущем разделе, каждая лингвистическая единица имеет как контрастивную, так и комбинаторную функцию. Понятно, что две единицы не могут противопоставляться, если они не являются по крайней мере частично эквивалентными по дистрибуции (для единиц, находящихся в отношении дополнительной дистрибуции, вопроса о контрастности не возникает). Единицы, встречающиеся в некотором данном контексте, но не контрастирующие одна с другой, находятся в отношении свободного варьирования. Например, гласные двух слов leap 'прыгать' и get 'получать' контрастируют в большинстве контекстов, в которых они обе встречаются (ср. bet 'пари': beat 'бить' и т. д.), но находятся в отношении свободного варьирования в альтернативных вариантах произношения слова economics 'экономика'. И в фонологии, и в семантике следует избегать смешения свободного варьирования (эквивалентность функции в контексте) с эквивалентной дистрибуцией (появление в одних и тех же окружениях). Что именно подразумевается под свободным варьированием и контрастом, зависит от природы единиц, к которым применяются эти термины, и от той точки зрения, с которой они рассматриваются. Как мы видели, два элемента выражения находятся в отношении контрастности, если в результате замены одного из них на другой получается новое слово или предложение; в противном случае они находятся в отношении свободного варьирования. Но слова (и другие грамматические единицы) можно рассматривать с двух различных точек зрения. Только в тех случаях, когда речь идет об их грамматической функции (то есть, грубо говоря, об их принадлежности к существительным, глаголам или прилагательным и т. д.), понятия контраста и свободного варьирования интерпретируются в терминах эквивалентной дистрибуции; это объясняется наличием прямой связи между грамматической функцией и дистрибуцией (ср. § 4.2.6). Хотя между значением слова и его дистрибуцией также существует известная связь, ни одно из них не определяется другим полностью; и поэтому эти два понятия различаются теоретически. В семантике свободное варьирование и контраст следует толковать как «тождество и различие значений». (Более принято, однако, использовать в семантике традиционный термин «синонимия», а не «свободное варьирование».) 2.3.3. «ПАРАДИГМАТИКА» И «СИНТАГМАТИКА» Благодаря возможности своего появления в определенном контексте языковая единица вступает в отношения двух разных типов. Она вступает в парадигматические отношения со всеми единицами, которые также могут встретиться в данном контексте (независимо от того, находятся ли они в отношении контрастности или свободного варьирования с рассматриваемой единицей), и в синтагматические отношения с другими единицами того же уровня, вместе с которыми она встречается и которые образуют ее контекст. Возвратимся к примеру, использованному нами в предыдущем разделе: в силу возможности своего появления в контексте /-et/ элемент выражения /b/ находится в парадигматическом отношении с /р/, /s/ и т. д. и в синтагматическом отношении с /е/ и /t/. Точно так же /е/ находится в парадигматическом отношении с /i/, /а/ и т. д. и в синтагматическом отношении с /b/ и /t/, а /t/ связано парадигматически с /d/, /n/ и т. д. и синтагматически с /b/ и /e/. Парадигматические и синтагматические отношения релевантны также на уровне слов и, собственно говоря, на любом уровне лингвистического описания. Например, слово pint 'пинта', благодаря возможности появления в таких контекстах, как а. . . of milk'. . .молока', вступает в парадигматические отношения с другими словами — такими, как bottle 'бутылка', cup 'чашка', gallon 'галлон' и т. д., и в синтагматические отношения с a, of и milk. Слова (и другие грамматические единицы) в действительности вступают в парадигматические и синтагматические отношения различных типов. «Возможность появления» можно интерпретировать, обращая внимание на то, является ли получающееся в результате словосочетание или предложение осмысленным, либо безотносительно к этому; с учетом ситуаций, в которых производятся реальные высказывания, либо независимо от этого; учитывая зависимости между различными предложениями в связной речи, либо не учитывая их и т. д. Ниже нам придется остановиться подробнее на различных ограничениях, которые могут налагаться на толкование термина «возможность появления» (см. § 4.2.1 о понятии «приемлемость»). Здесь следует подчеркнуть, что все языковые единицы вступают в синтагматические и парадигматические отношения с единицами того же уровня (элементы выражения с элементами выражения, слова со словами и т. д.), что контекст языковой единицы может быть точно определен в терминах ее синтагматических отношений и что определение множества контекстов, в которых единица может встретиться, так же как и объема класса единиц, с которыми она вступает в парадигматические отношения, зависит от интерпретации, эксплицитно или имплицитно придаваемой понятию «возможности появления» (или «приемлемости»). Может показаться, что последнее положение излишне усложняет вопрос. Позднее станет ясно, что одно из преимуществ данной формулировки состоит в том, что она позволяет нам разграничить грамматически правильные и осмысленные предложения не в терминах сочетания грамматических единиц в одном случае и семантических единиц («значений») в другом, а в терминах степени или вида «приемлемости», сохраняемой различными сочетаниями одних и тех же единиц. 2.3.4. ВЗАИМОЗАВИСИМОСТЬ ПАРАДИГМАТИЧЕСКИХ И СИНТАГМАТИЧЕСКИХ ОТНОШЕНИЙ Теперь можно сделать два важных утверждения о парадигматических и синтагматических отношениях. Первое из них, которое (наряду с разграничением субстанции и формы) может рассматриваться как определяющая черта современной, «структурной» лингвистики, звучит так: языковые единицы не имеют значимости вне парадигматических и синтагматических отношений с другими единицами. (Это более конкретная формулировка общего «структурального» принципа, гласящего, что всякая языковая единица имеет свое определенное место в системе отношений: см. § 1.4.6.) Вот иллюстрация из уровня элементов выражения. В предшествующем рассмотрении таких английских слов, как bet, pet и т. д., предполагалось, что каждое из этих слов реализуется последовательностью из трех элементов выражения (подобно тому, как они записываются последовательностями из трех букв в принятой орфографии). Теперь можно проверить это предположение. Допустим, вопреки фактам, что существуют слова, реализующиеся как put, tit, cat, pup, tip, cap, puck и tick, но не существует слов, реализующихся («произносимых») как but, pet, pit, bit, cut, gut, kit, duck, cab, cad, kid, cud и т. д. Иными словами, мы предполагаем (удовлетворяясь достаточно неточными фонетическими терминами), что все фонологические слова, представленные комплексами из трех звуков, можно описать с точки зрения их субстанциальной реализации (то есть в качестве фонетических слов) как последовательности согласный+гласный+согласный (где согласные — это [р], [t] или [k], а гласные — [u], [i] и [а] — для простоты предположим, что не существует других согласных или гласных), но что в первой и второй позиции возможны только такие сочетания согласного и гласного, как [pu], [ti] и [ka]. В таком случае ясно, что [u], [i] и [а] не являются реализацией трех различных элементов выражения, поскольку они не находятся в парадигматическом отношении (и, a fortiori, в отношении контрастности). Сколько именно элементов выражения выделяется в подобной ситуации (которая не является чем-то исключительным по сравнению с тем, что обычно встречается в языке) — зависит от некоторых более частных фонологических принципов, которые мы обсудим ниже. Можно считать, что в каждом слове выделяются только две позиции контрастности, из которых первая «заполняется» одним из трех консонантно-вокальных комплексов, а вторая — одним из трех согласных: тогда мы выделим шесть элементов выражения (реализуемых как /1/ : [ka], /2/ : [pu], /3/ : [ti], /4/ : [р], /5/ : [t] и /6/: [k]). С другой стороны, можно выделять четыре элемента выражения, из которых три реализуются согласными [р], [t] и [к], встречающимися в начальном и конечном положении, а четвертый, фигурирующий в срединной позиции, реализуется гласным, фонетическое качество которого определяется предшествующим согласным. Дело, следовательно, в том, что нельзя сначала установить элементы, а затем устанавливать их допустимые сочетания. Элементы определяются посредством одновременного учета их парадигматических и синтагматических связей. Причина того, что мы выделяем три позиции контрастности в английских словах bet, pet, bit, pit, bid, tip, tap и т. д., заключается в том, что парадигматические и синтагматические связи могут быть установлены в трёх точках. Мы увидим, что взаимозависимость парадигматических и синтагматических измерений представляет собой принцип, применимый ко всем уровням языковой структуры. 2.3.5. «СИНТАГМАТИЧЕСКОЕ» НЕ ПОДРАЗУМЕВАЕТ «ЛИНЕЙНОЕ» Вторым важным утверждением является следующее: синтагматические связи не обязательно предполагают упорядоченность единиц в линейную последовательность, такую, что субстанциальная реализация одного элемента предшествует во времени субстанциальной реализации другого. Сравним, например, два китайских слова — ha?o ('день') и ha?o ('хороший'), — которые отличаются друг от друга фонологически тем, что первое произносится с интонацией, условно обозначаемой как «четвертый тон» (/?/), реализуемый как понижение тона в течение слога), а второе произносится с «третьим тоном» (/?/, реализуемым как повышение тона в течение слога со среднего тона до высокого и снова понижение до среднего). Эти два элемента — /?/ и /?/ — находятся в отношении парадигматической контрастности в контексте /hao/; другими словами, в этом контексте (и во многих других) они вступают в одни и те же синтагматические отношения. Если мы скажем, что одно слово следует анализировать фонологически как /hao/+/?/, а другое — как /hao/+/?/, это, естественно, не означает, что субстанциальная реализация тона следует за субстанциальной реализацией остальной части слова. Языковые высказывания произносятся во времени и, следовательно, могут быть сегментированы как цепочка последовательных звуков или комплексов звуков. Однако является ли это следование во времени релевантным для структуры языка, зависит опять-таки от парадигматических и синтагматических связей языковых единиц и не зависит, в принципе, от сукцессивности их субстанциальных реализаций. Относительная последовательность представляет собой одно из свойств звуковой субстанции (в случае графической субстанции эта особенность отражается в пространственной упорядоченности элементов — слева направо, справа налево или сверху вниз, в зависимости от принятой системы письма), которое может быть, а может и не быть использовано языком. Сказанное лучше всего проиллюстрировать примером, относящимся к грамматическому уровню. Английский язык обычно называют языком с «фиксированным порядком слов», а латынь — это язык со «свободным порядком слов». (В действительности, порядок слов в английском языке не является полностью «фиксированным», а порядок слов в латыни — абсолютно «свободным», но разница между этими двумя языками достаточно ясна для целей настоящей иллюстрации.) В частности, английское предложение, состоящее из подлежащего, сказуемого и прямого дополнения (напр., Brutus killed Caesar 'Брут убил Цезаря'), в нормальных условиях произносится (и пишется) с субстанциальными реализациями трех рассматриваемых единиц, упорядоченными в виде последовательности подлежащее + сказуемое + прямое дополнение; перемена мест двух существительных, или именных составляющих, приводит к тому, что предложение становится не грамматичным или превращается в другое предложение: Brutus killed Caesar 'Брут убил Цезаря' и Caesar killed Brutus 'Цезарь убил Брута' — это разные предложения; в то время как The chimpanzee ate some bananas 'Шимпанзе поела бананов' является предложением, Some bananas ate the chimpanzee таковым (как можно думать) не является. Напротив, Brutus necavit Caesarem и Caesarem necavit Brutus суть альтернативные субстанциальные реализации одного и того же предложения ('Брут убил Цезаря') так же, как Caesar necavit Brutum и Brutum necavit Caesar ('Цезарь убил Брута'). Относительный порядок, в котором слова располагаются в латинском предложении, следовательно, грамматически нерелевантен, хотя, конечно, слова нельзя произносить иначе, как в том или ином конкретном порядке. 2.3.6. ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СИНТАГМАТИЧЕСКИЕ ОТНОШЕНИЯ Теперь сформулируем наше утверждение в более общем виде. Для простоты предположим, что мы имеем дело с двумя классами (ориентировочно выделенных) единиц, причем члены каждого класса находятся в парадигматических связях друг с другом. Это классы X с членами а и b и Y с членами р и q; употребляя стандартное обозначение для выражения принадлежности к классу, получаем: Х = {а, b}, Y = {p, q}. (Эти формулы можно прочесть так: «X — это класс, членами которого являются а и b», «Y — это класс, членами которого являются р и q».) Субстанциальная реализация каждой единицы представлена соответствующей курсивной буквой (а реализует а и т. д., а X и Y суть переменные, обозначающие реализации единиц). Допустим, что эти субстанциальные реализации не могут встречаться одновременно (это могут быть согласные и гласные или слова), но линейно упорядочены по отношению друг к другу. В этом случае следует учитывать три возможности: (i) последовательность может быть «фиксированной» в том смысле, что, скажем, X непременно предшествует Y (то есть встречаются ар, aq, bp, bq, но не pa, qa, pb, qb); (ii) последовательность может быть «свободной», в том смысле, что встречаются как XY, так и YX, но XY = YX (где ' = ' означает 'эквивалентно' — эквивалентность определяется для того или иного конкретного уровня описания); (iii) последовательность может быть «фиксированной» (или «свободной») в том, несколько ином смысле, что встречаются как XY, так и YX, но XY ? YX ('?' означает 'не эквивалентно'). Заметим мимоходом, что эти три возможности не всегда разграничиваются при рассмотрении таких вопросов, как порядок слов. Интерпретация последних двух из перечисленных трех возможностей не представляет теоретических трудностей. В случае (ii), поскольку XY и YX не контрастируют, единицы а, b, р и q, реализуемые в таких последовательностях, как ар или ра, находятся в нелинейном синтагматическом отношении (таково положение со словами в языках со свободным порядком слов). В случае (iii), поскольку XY контрастирует с YX, единицы находятся в линейном синтагматическом отношении (таково положение с прилагательным и существительным для некоторых французских прилагательных). С бo?льшими сложностями связана трактовка случая (i), кстати весьма обычного. Поскольку YX не встречается, члены классов X и Y не могут находиться в линейном отношении на этом уровне. С другой стороны, в каком-то месте описания языка следует указать обязательный порядок их реализации в субстанции; поэтому при обобщении правил, имеющих отношение к разным уровням, было бы выгодно объединить примеры из (iii) с примерами из (ii) [27]. Неявным образом обращаясь к этому принципу, мы говорили выше, что английские слова типа bet, pet и т. д. имеют фонологическую структуру согласный + гласный + согласный (используя термины «согласный» и «гласный» для классов элементов выражения). То, что некоторые синтагматические отношения в английском языке являются линейными, ясно из сравнения таких слов, как pat 'шлепок', apt 'подходящий', cat 'кошка', act 'акт' и т. д. Последовательности CCV (согласный + согласный + гласный; речь идет о согласных, реализуемых как [р], [t], [k], [b], [d] и [g]) невозможны, однако встречаются, как мы только что видели, как последовательности CVC, так и, по крайней мере несколько примеров, VCC. В то же время имеются систематические ограничения на совместное появление согласных в последовательности VCC; например, слово, которое реализовалось бы в субстанции как [atp] или [atk], систематически исключается, точно так же, как и [akk], [арр], [att]. В фонологической структуре рассматриваемых английских слов экземплифицированы, следовательно, как случай (i), так и случай (iii). Сводя их к одной и той же упорядочивающей формуле, мы упрощаем утверждение об их субстанциональной реализации. Следует, однако, подчеркнуть, что это не означает, что мы должны отказаться от выявления разницы между такими «случайными» пробелами в английском словаре, как [git] или [ped], и такими системно исключаемыми 'словами', как [pti] или [atp] (ср. § 2.3.1). Дальнейшее обсуждение вопросов, связанных с линейной организацией элементов, будет здесь неуместно. Мы вернемся к нему ниже. Но прежде чем продолжать изложение, следует подчеркнуть, что настоящее рассуждение преднамеренно ограничено предположением, что все единицы, находящиеся в синтагматической связи, обладают равными возможностями совместной встречаемости и что не существует никаких группировок внутри комплексов таких единиц. Может также показаться, что наше рассуждение основывается на дополнительно вводимом предположении, что каждая единица непременно реализуется одним и только одним выделимым сегментом или признаком звуковой субстанции. Это не так, как мы увидим позже. Наши два общих утверждения сводятся к следующему: (1) парадигматические и синтагматические измерения взаимозависимы и (2) синтагматическое измерение не обязательно упорядочено во времени. 2.3.7. «МАРКИРОВАННОСТЬ» И «НЕМАРКИРОВАННОСТЬ» * До сих пор мы выделили только два типа возможных отношений для парадигматически связанных единиц: они могут находиться в отношении контрастности или свободного варьирования. Часто бывает так, что из двух единиц, находящихся в отношении контрастности (для простоты мы можем ограничиться двучленными контрастами), одна выступает как положительная, или маркированная, тогда как другая — как нейтральная, или немаркированная. Поясним на примере, что имеется в виду под этими терминами. Большинство английских существительных имеет родственные формы множественного и единственного числа, подобно таким словам, как boys: boy, days: day, birds: bird и т. д. Множественное число маркировано конечным s, тогда как единственное не маркировано. Другой способ выразить то же самое — это сказать, что в том или ином контексте наличие определенной единицы контрастирует с ее отсутствием. Когда имеет место подобное положение, немаркированная форма обычно имеет более общее значение или же более широкую дистрибуцию по сравнению с маркированной формой. В связи с этим стало обычным использование терминов «маркированность» и «немаркированность» в несколько более абстрактном смысле, так что маркированный и немаркированный члены контрастирующей пары не обязательно различаются наличием или отсутствием какой-то определенной единицы. Например, с семантической точки зрения слова dog 'собака, пес' и bitch 'сука' являются соответственно немаркированным и маркированным в отношении противопоставления по полу. Слово dog семантически не маркировано (или нейтрально), поскольку оно может относиться и к самцам и к самкам (That's a lovely dog you've got there: is it a he or a she? 'У вас очаровательная собака: это он или она?'). Однако bitch маркировано (или положительно), поскольку его употребление ограничено обозначением самок, и оно может использоваться по контрасту с немаркированным термином, определяя значение последнего как отрицательное, а не нейтральное (Is it a dog or a bitch? 'Это кобель или сука?'). Другими словами, немаркированный терм имеет более общее значение, нейтральное по отношению к определенному противопоставлению; его более специфическое отрицательное значение является производным и вторичным, будучи следствием его контекстуальной оппозиции с позитивным (не нейтральным) термом. Особый характер отношения между словами dog и bitch является объяснением того, что female dog 'самка собаки' и male dog 'самец собаки' совершенно приемлемы, а сочетания female bitch 'самка суки' и male bitch 'самец суки' семантически аномальны: одно тавтологично, а другое противоречиво. Понятие «маркированности» внутри парадигматических оппозиций чрезвычайно важно для всех уровней языковой структуры. 2.3.8. СИНТАГМАТИЧЕСКАЯ ДЛИНА Здесь можно сделать последнее общее утверждение относительно связи парадигматического и синтагматического измерений. Если дано некоторое множество единиц, различающихся с помощью элементов «низшего уровня», из которых они состоят, то (независимо от определенных статистических соображений, которые будут рассмотрены в следующем разделе) длина каждой из единиц «высшего уровня», измеряемая с точки зрения числа синтагматически связанных элементов, отождествляющих данный комплекс, будет обратно пропорциональна числу элементов, находящихся в отношении парадигматической контрастности в пределах этого комплекса. Предположим, например, что в некоторой системе есть только два элемента выражения (которые мы обозначим как 0 и 1) и что в некоторой другой системе представлено восемь элементов выражения (которые мы занумеруем цифрами от 0 до 7); для простоты, поскольку такое предположение не затрагивает общего принципа, допустим, что любые комбинации элементов выражения разрешаются «фонологическими» правилами, которым подчиняются обе системы. Чтобы различить восемь «фонологических» слов в рамках первой (бинарной) системы, каждое из слов должно состоять по крайней мере из трех элементов (000, 001, 010, 011, 100, 101, 110, 111), тогда как во второй (октальной) системе для различения каждого из восьми слов достаточно одного элемента (0, 1, 2, 3, 4, 5, 6, 7). Чтобы различить 64 слова, в бинарной системе нужны комплексы, состоящие не менее чем из шести элементов, а в восьмеричной — не менее чем из двух элементов. В общем, максимальное [28] число единиц «высшего уровня», которые могут различаться с помощью некоторого множества элементов «низшего уровня», синтагматически связанных в комплексах, определяется формулой: N = p1 ? р2 ? р3 ... рm (где N — число единиц «высшего уровня», m — число позиций парадигматического контраста для элементов «низшего уровня», p1 обозначает число элементов, вступающих в отношение парадигматической контрастности в первой позиции, р2 обозначает число элементов, вступающих в отношение парадигматической контрастности во второй позиции, и так далее до m-ной позиции). Отметим, что эта формула не предполагает ни того, что во всех позициях могут появляться одни и те же элементы, ни того, что во всех позициях число элементов, находящихся в парадигматическом контрасте, одно и то же. То, что было сказано выше в связи с простым примером двоичной и восьмеричной систем, внутри которых все элементы встречаются во всех положениях и возможны любые синтагматические сочетания, таким образом, представляет собой не более чем частный случай, подпадающий под более общую формулу: 2 ? 2 ? 2 = 8, 2 ? 2 ? 2 ? 2 = 16 и т. д. и 8 = 8, 8 ? 8 = 64, 8 ? 8 ? 8 = 512 и т. д. Основанием, в связи с которым мы выбрали для сравнения бинарную систему (с двумя элементами) и восьмеричную систему (с восемью элементами), является то обстоятельство, что 8 — это целая степень от 2: это 2 в 3-й степени, а не 2 в степени 3,5 или 4,27 и т. п. Это четко выявляет связь между парадигматическим контрастом и синтагматической «длиной». При прочих равных условиях минимальная длина слов в бинарной системе в три раза больше длины слов в восьмеричной системе. Мы используем это частное числовое соотношение в следующем разделе. В последующих главах, особенно в главе, посвященной семантике, мы обратимся к более общему принципу, согласно которому лингвистически существенные различия могут проводиться как на основе синтагматических, так и на основе парадигматических критериев. Отметим, что понятие «длины», которое мы только что рассмотрели, определяется в зависимости от числа позиций парадигматического контраста в пределах синтагматического комплекса. Оно не обязательно связано с временной последовательностью. Это положение (вытекающее из сказанного ранее в настоящем разделе — см. § 2.3.6) весьма существенно для последующего обсуждения фонологической, грамматической и семантической структур. 2.4. СТАТИСТИЧЕСКАЯ СТРУКТУРА * 2.4.1. ФУНКЦИОНАЛЬНАЯ НАГРУЗКА * Не все парадигматические противопоставления, или контрасты, в равной степени существенны для функционирования языка. Они могут значительно отличаться друг от друга по своей функциональной нагрузке. Чтобы пояснить значение этого термина, можно рассмотреть некоторые противопоставления в пределах фонологической системы английского языка. Субстанциальная реализация многих слов устного английского языка различается тем, что в одном и том же окружении в одних случаях встречается [p], а в других — [b] (ср. pet : bet, pin : bin, pack : back, cap : cab и т. д.); на основе этого контраста мы можем установить оппозицию между /р/ — /b/, которые, по крайней мере на этом этапе, мы можем рассматривать как два минимальных элемента выражения языка (под «минимальной» мы подразумеваем далее не разложимую единицу). Поскольку многие слова различаются благодаря оппозиции /р/ — /b/, контраст между этими двумя элементами несет высокую функциональную нагрузку. Другие противопоставления несут более низкую функциональную нагрузку. Например, относительно небольшое число слов различается в субстанциальной реализации наличием одного, а не другого из двух согласных, которые встречаются в конечном положении в словах wreath 'венок' и wreathe 'плести венки' (символы этих двух звуков в Международном Фонетическом Алфавите — соответственно [?] и [?]; ср. § 3.2.8); весьма небольшое количество слов, если они вообще существуют, отличается друг от друга противопоставлением звука, фигурирующего в начале слова ship, звуку, представленному вторым согласным в словах measure или leisure (эти два звука обозначаются в Международном Фонетическом Алфавите соответственно [?] и [?]). Функциональная нагрузка контрастов между [?] и [?] и между [?] и [?] таким образом намного ниже, чем функциональная нагрузка контраста /р/ : /b/. Значение функциональной нагрузки очевидно. Если говорящие на некотором языке не сохраняют последовательно те противопоставления, благодаря которым высказывания с разным значением отличаются друг от друга, то это может привести к неправильному пониманию. При прочих равных условиях (мы еще к этому вернемся) чем выше функциональная нагрузка, тем более важно, чтобы говорящие овладели отдельным противопоставлением как частью своих «речевых навыков» и последовательно сохраняли его при своем использовании языка. Следует ожидать поэтому, что дети раньше всего овладевают контрастами, несущими наиболее высокую функциональную нагрузку в том языке, который они слышат; соответственно, противопоставления с высокой функциональной нагрузкой, по-видимому, также лучше сохраняются при передаче языка от одного поколения к другому. Наблюдая, с какой легкостью дети овладевают контрастами своего родного языка, и изучая историческое развитие отдельных языков, мы получаем некоторое эмпирическое подтверждение этим предположениям. Впрочем, в каждом случае имеются дополнительные факторы, которые взаимодействуют с принципом функциональной нагрузки и которые трудно отделить от этого последнего. Здесь мы эти факторы рассматривать не будем. Точная оценка функциональной нагрузки усложняется, если не становится абсолютно невозможной, из-за соображений, которые нам позволила временно не принимать во внимание оговорка «при прочих равных условиях». Во-первых, функциональная нагрузка отдельного противопоставления между элементами выражения варьирует в зависимости от структурной позиции, занимаемой ими в слове. Например, два элемента могут часто противопоставляться в начале слова, но очень редко — в конце слова. Берем ли мы просто среднюю величину для всех позиций контраста? Ответ на этот вопрос не ясен. Во-вторых, значение отдельного противопоставления между элементами выражения не есть просто функция от числа различаемых ими слов: оно также зависит от того, могут ли эти слова встречаться и контрастировать в одном и том же контексте. Возьмем предельный случай: если А и В — два класса слов, находящихся в дополнительной дистрибуции, и каждый член класса А отличается в субстанциальной реализации от какого-то члена класса В только тем, что в нем представлен элемент /а/ там, где в соответствующем слове из В представлен элемент /b/, то функциональная нагрузка контраста между /а/ и /b/ равна нулю. Таким образом, функциональную нагрузку отдельного противопоставления следует подсчитывать для слов, имеющих одну и ту же или частично совпадающую дистрибуцию. Ясно также, что всякий «реалистический» критерий оценки значения отдельного контраста должен учитывать не просто дистрибуцию слов, устанавливаемую грамматическими правилами, но реальные высказывания, которые можно было бы перепутать, если не сохранять этот контраст. Например, как часто или в каких обстоятельствах такое высказывание, как You'd better get a cab 'Вам лучше бы взять такси', можно было бы спутать с высказыванием You'd better get a cap 'Вам бы лучше получить кепку', если бы говорящий не различал конечных согласных слов cab и cap? Ответ на этот вопрос, очевидно, существен для любой точной оценки рассматриваемого контраста. Наконец, значение отдельного контраста, по-видимому, связано с частотой его встречаемости (которая не обязательно определяется числом различаемых им слов). Допустим, что три элемента выражения — /х/, /у/ и /z/ — встречаются в одной и той же структурной позиции в словах одного дистрибутивного класса. Но предположим далее, что тогда как слова, в которых встречаются /х/ и /у/, часто противопоставлены в языке (это высокочастотные слова), слова, в которых встречается /z/, характеризуются низкой частотой появления (хотя они могут быть столь же многочисленны в словаре). Если носитель языка не будет владеть контрастом между /х/ и /z/, общение для него будет затруднено в меньшей степени, чем в том случае, если он не будет владеть контрастом между /х/ и /y/. Функциональная нагрузка последнего контраста, ex hypothesi, выше, чем первого. Соображения, высказанные в предыдущих параграфах, показывают, как трудно прийти к какому-либо точному критерию оценки функциональной нагрузки. Разнообразные критерии, предложенные лингвистами до сих пор, не могут претендовать на точность, несмотря на свою математическую изощренность. Тем не менее следует предусмотреть в нашей теории языковой структуры место для понятия функциональной нагрузки, несомненно весьма важного как в синхроническом, так и в диахроническом плане. Очевидно, все же имеет смысл говорить о том, что определенные противопоставления несут более высокую функциональную нагрузку, чем какие-то другие, даже если соответствующие различия не поддаются точному измерению. 2.4.2. КОЛИЧЕСТВО ИНФОРМАЦИИ И ВЕРОЯТНОСТЬ ПОЯВЛЕНИЯ * Другое важное статистическое понятие связано с количеством информации, которую несет языковая единица в некотором данном контексте; оно также определяется частотой появления в этом контексте (во всяком случае, так обычно считается). Термин «информация» употребляется здесь в особом значении, которое он приобрел в теории связи и которое мы сейчас поясним. Информационное содержание отдельной единицы определяется как функция от ее вероятности. Возьмем для начала самый простой случай: если вероятности появления двух или более единиц в некотором данном контексте равны, каждая из них несет в этом контексте одно и то же количество информации. Вероятность связана с частотой следующим образом. Если две, и только две, равновероятные единицы — х и у — могут встретиться в рассматриваемом контексте, каждая из них встречается (в среднем) ровно в половине всех соответствующих случаев: вероятность каждой, a priori, равна 1/2. Обозначим вероятность отдельной единицы х через рх. Итак, в данном случае рх = 1/2 и ру = 1/2. В более общем виде вероятность каждой из n равновероятных единиц (x1, х2, х3, . . ., хn) равна 1/n. (Заметим, что сумма вероятностей всего множества единиц равна 1. Это справедливо независимо от более частного условия равной вероятности. Особым случаем вероятности является «достоверность». Вероятность появления единиц, которые не могут не появиться в данном контексте, равна 1.) Если единицы равновероятны, каждая из них несет одно и то же количество информации. Более интересны, поскольку более типичны для языка, неравные вероятности. Предположим, например, что встречаются две, и только две, единицы, х и у, и что х встречается в среднем вдвое чаще, чем у, тогда рх = 2/3 и ру = 1/3. Информационное содержание x вдвое меньше, чем содержание у. Другими словами, количество информации обратно пропорционально вероятности (и, как мы увидим, логарифмически связано с ней): это фундаментальный принцип теории информации. С первого взгляда это может показаться несколько странным. Однако рассмотрим сначала предельный случай полной предсказуемости. В письменном английском языке появление буквы u, когда она следует за q, почти полностью предсказуемо; если отвлечься от некоторых заимствованных слов и собственных имен, можно сказать, что оно полностью предсказуемо (его вероятность равна 1). Подобно этому, вероятность слова to в таких предложениях, как I want . . . go home, I asked him . . . help me [29] (предполагается, что пропущено только одно слово), равна 1. Если бы мы решили опустить u (в queen 'королева', queer 'странный', inquest 'следствие' и т. п.) или слово to в упомянутых контекстах, никакой информации не было бы потеряно (здесь мы наблюдаем связь между обычным и более специальным значением слова «информация»). Поскольку буква u и слово to не находятся в парадигматическом контрасте ни с какими другими единицами того же уровня, которые могли бы встретиться в том же контексте, вероятность их появления равна 1, а их информационное содержание — 0; они целиком избыточны. Рассмотрим теперь случай двучленного контраста, где рх = 2/3 и ру = 1/3. Ни один из членов не является целиком избыточным. Но ясно, что пропуск х приводит к меньшим последствиям, чем пропуск у. Поскольку появление х вдвое вероятнее, чем появление у, получатель сообщения (знающий априорные вероятности) имеет в среднем вдвое лучшие шансы «угадать» пропуск х, чем «угадать» пропуск у. Таким образом, избыточность проявляется в различной степени. Избыточность х в два раза больше, чем избыточность у. В общем, чем более вероятно появление единицы, тем большей оказывается степень ее избыточности (и тем ниже ее информационное содержание). 2.4.3. БИНАРНЫЕ СИСТЕМЫ Количество информации обычно измеряется в битах (этот термин происходит от англ. binary digit 'двоичный знак'). Всякая единица с вероятностью появления 1/2 содержит один бит информации; всякая единица с вероятностью 1/4 несет 2 бита информации, и так далее. Удобство такого измерения количества информации станет очевидным, если мы обратимся к практической задаче «кодирования» множества единиц (сначала предположим, что вероятности их появления равны) группами двоичных знаков. В предыдущем разделе мы видели, что каждый элемент множества из восьми единиц может быть реализован отдельной группой из трех двоичных знаков (см. § 2.3.8). Это определяется связью между числом 2 (основанием двоичной системы исчисления) и 8 (количеством единиц, которые требуется различать): 8 = 23. В более общем виде, если N — это число единиц, которые следует различать, a m — это число позиций контраста в группах двоичных знаков, требуемых для их различения, то N = 2m. Связь между числом парадигматических контрастов на «высшем» уровне (N) и синтагматической длиной групп элементов «низшего» уровня (m), таким образом, логарифмическая: m = log2 N. (Логарифм числа есть степень, в которую следует возвести основание числовой системы, чтобы получить данное число. Если N = xm, то m = logx N 'если N равняется х в степени m, то m равняется логарифму N по основанию x'. Напомним, что в десятичной арифметике логарифм 10 равен 1, логарифм 100 равен 2, логарифм 1000 равен 3 и т. д., т. е. log10 10 = 1, log10 100 = 2, log10 1000 = 3 и т. д. Если бы теория информации основывалась на десятичной, а не на двоичной системе измерения, то было бы удобнее определять единицу информации в терминах вероятности 1/10. Читателю должно быть ясно, что приведенное здесь равенство N = 2m — это частный случай равенства N = р1 ? р2 ? р3, ..., рm, введенного в § 2.3.8. Равенство N = 2m справедливо, если в каждой позиции синтагматической группы в парадигматическом контрасте находится одно и то же число элементов. Количество информации измеряется обычно в битах, просто потому, что многие механические системы для хранения и передачи информации действуют на основе бинарного принципа: это системы с двумя состояниями. Например, информацию можно закодировать на магнитной ленте (для обработки с помощью цифровой ЭВМ) как последовательность намагниченных и ненамагниченных позиций (или групп позиций): каждая позиция находится в одном из двух возможных состояний и может, таким образом, нести один бит информации. Кроме того, информацию можно передавать (как, например, в азбуке Морзе) в виде последовательности «импульсов», каждый из которых принимает одно из двух значений: короткий или длинный по продолжительности, положительный или отрицательный по электрическому заряду и т. п. Всякая система, использующая «алфавит», состоящий более чем из двух элементов, может быть перекодирована в бинарную систему у источника передачи и снова перекодирована в первоначальный «алфавит», когда сообщение получено по месту назначения. Это имеет место, например, при передаче сообщений по телеграфу. То, что информационное содержание должно измеряться с помощью логарифмов с основанием 2, а не логарифмов с каким-либо другим числовым основанием, есть следствие того факта, что инженеры связи обычно работают с системами с двумя состояниями. Что касается вопроса об уместности применения принципа двоичного «кодирования» именно при исследовании языка в нормальных условиях «передачи» от говорящего к слушающему, то он вызывает значительные разногласия среди лингвистов. Не подлежит сомнению, что многие наиболее важные фонологические, грамматические и семантические различия бинарны, как мы увидим в последующих главах; мы уже видели, что один из двух членов бинарной оппозиции может рассматриваться как положительный, или маркированный, а другой — как нейтральный, или немаркированный (см. § 2.3.7). Мы не будем вдаваться здесь в обсуждение вопроса, можно ли свести все лингвистические единицы к комплексам иерархически упорядоченных бинарных «выборов». Тот факт, что многие единицы (на всех уровнях языковой структуры) сводимы к ним, означает, что лингвисту следует приучиться мыслить в терминах бинарных систем. В то же время следует отдавать себе отчет в том, что фундаментальные идеи теории информации совершенно не зависят от частных предположений относительно бинарности. 2.4.4. НЕРАВНЫЕ ВЕРОЯТНОСТИ Поскольку каждый двоичный знак несет только один бит информации, группа из m двоичных знаков может нести максимум m битов. До сих пор мы предполагали, что вероятности различаемых таким образом единиц высшего уровня равны. Теперь рассмотрим более интересный и более обычный случай, когда эти вероятности не равны. Для простоты возьмем множество из трех единиц, а, b и с, со следующими вероятностями: ра = 1/2, рb = 1/4, pс = 1/4. Единица а несет 1 бит, а b и с несут по 2 бита информации каждая. Их можно закодировать в двоичной системе реализации, как а : 00, b : 01 и с : 10 (оставив 11 незанятым). Но если бы знаки передавались в последовательности по некоторому каналу связи и передача и получение каждого знака занимали бы один и тот же отрезок времени, было бы неразумным принимать столь неэффективное условие кодирования. Ведь для а требовалась бы такая же мощность канала, как для b и для с, хотя оно несло бы вдвое меньше информации. Более экономичным было бы закодировать а с помощью одного знака, скажем 1, и отличать b и с от а, закодировав их противоположным знаком — 0 — в первой позиции; b и с тогда отличались бы друг от друга во второй позиции контраста (которая, конечно, пуста для а). Итак, а : 1, b : 00 и с : 01. Это второе соглашение более экономичным образом использует пропускную способность канала, так как оно увеличивает до предела количество информации, которое несет каждая группа в один или два знака. Поскольку на передачу а, которое встречается вдвое чаще, чем b и c, тратится вдвое меньше времени, данное решение позволило бы в кратчайшее время передать наибольшее число сообщений (исходя из предположения, что эти сообщения достаточно длинны или достаточно многочисленны, чтобы отражать средние частоты появления). В действительности эта простая система представляет собой теоретический идеал: каждая из трех единиц a, b и с несет целое число битов информации и реализуется в субстанции именно этим числом различий. 2.4.5. ИЗБЫТОЧНОСТЬ И ШУМ Этот теоретический идеал никогда не достигается на практике. Прежде всего вероятности появления единиц обыкновенно находятся между величинами ряда 1, 1/2, 1/4, 1/8, 1/16, . . . , 1/2m, а не соответствуют им в точности. Например, вероятность появления отдельной единицы может быть равна 1/5, поэтому она может передавать log2 5 — приблизительно 2,3 — бита информации. Но в субстанции не бывает различия, измеряемого числом 0,3; субстанциальные различия абсолютны в поясненном выше смысле (см. § 2.2.10). Если же мы используем три знака для отождествления единицы с вероятностью появления в 1/5, мы тем самым введем избыточность в субстанциальную реализацию. (Среднюю избыточность системы можно сделать сколь угодно малой; математическая теория связи занимается-главным образом этой задачей. Но нам здесь нет необходимости вдаваться в более специальные подробности.) Важным является то, что некоторая степень избыточности на самом деле желательна в любой системе связи. Причина состоит здесь в том, что, какая бы среда ни использовалась в целях передачи информации, она будет подвержена разнообразным непредсказуемым природным помехам, которые уничтожат или исказят часть сообщения и таким образом приведут к потере информации. Если бы система была свободна от избыточности, потеря информации была бы невосполнима. Инженеры связи обозначают случайные помехи в среде или канале связи термином шумы. Оптимальная система для отдельного канала такова, что в ней ровно столько избыточности, сколько требуется, чтобы получатель мог восстановить информацию, потерянную из-за шумов. Заметим, что термины «канал» и «шумы» следует толковать в самом общем смысле. Их применение не ограничивается акустическими системами и тем более системами, созданными инженерами (телефон, телевизор, телеграф и т. п.). Искажения в почерке, получающиеся при письме в движущемся поезде, можно также причислить к «шумам»; сюда же относятся искажения, возникающие в речи при насморке, в состоянии опьянения, от рассеянности или ошибок памяти и т. п. (Опечатки — это одно из следствий воздействия шумов при «кодировании» письменного языка; читатель часто не замечает их, потому что избыточность, характерная для большей части письменных предложений, достаточна для того, чтобы нейтрализовать искажающее влияние случайных ошибок. Опечатки более существенны в цепочке знаков, любая комбинация которых a priori возможна. С этим на практике считаются бухгалтеры, которые умышленно вводят в свои книги избыточную информацию, требуя баланса сумм в разных колонках. Обычай ставить сумму к выплате на чеках и прописью и цифрами позволяет банкам обнаружить, если не исправить, многие ошибки, вызванные шумами того или иного рода.) Что же касается устной речи, то термин «шум» включает любой источник искажения или непонимания, относится ли он к недостаткам речевой деятельности говорящего и слушающего или к акустическим условиям физической среды, в которой производятся высказывания. 2.4.6. КРАТКОЕ ИЗЛОЖЕНИЕ ОСНОВНЫХ ПРИНЦИПОВ ТЕОРИИ ИНФОРМАЦИИ С начала 1950-х гг. теория связи (или теория информации) оказывает большое влияние на множество других наук, в том числе на лингвистику. Основные ее принципы можно резюмировать следующим образом: (i) Вся коммуникация основывается на возможности выбора, или селекции, из множества альтернатив. В главе, посвященной семантике, мы увидим, что этот принцип дает нам толкование термина «значимый» (в одном из смыслов): языковая единица любого уровня не обладает значением в некотором данном контексте, если она полностью предсказуема в этом контексте. (ii) Информационное содержание изменяется обратно пропорционально вероятности. Чем более предсказуема единица, тем меньше значения она несет. Этот принцип хорошо согласуется с мнением стилистов о том, что клише (или «избитые выражения» и «мертвые метафоры») менее действенны, чем более «оригинальные» обороты речи. (iii) Избыточность субстанциальной реализации языковой единицы (ее «кодирования») измеряется разницей между количеством отличительных признаков субстанции, требуемых для ее отождествления, и ее информационным содержанием. Определенная степень избыточности необходима для противодействия шумам. Наше предшествующее рассуждение об устойчивости субстанции, в которой реализуется язык, и о необходимости некоторого «запаса прочности», позволяющего различать реализации контрастирующих элементов, можно также подвести под более общий принцип избыточности (ср. § 2.2.10). (iv) Язык будет более эффективным (с точки зрения теории информации), если синтагматическая длина единиц будет обратно пропорциональна вероятности их появления. То, что в языке действительно имеет силу подобный принцип, подтверждается тем фактом, что наиболее употребительные слова и выражения обычно бывают более короткими. Это было сначала эмпирическим наблюдением, а не дедуктивным (подлежащим проверке) выводом из определенных теоретических предпосылок; в дальнейшем для выражения связи между длиной и частотой употребления была выработана специальная формула, известная как «закон Ципфа» (по имени ее автора). (Мы не будем приводить здесь «закон Ципфа» или обсуждать его математическую и лингвистическую основу; он подвергся видоизменениям в последующих работах.) В то же время следует признать, что длина слова в буквах или звуках (в том смысле, в каком мы употребляли термин «звук» до сих пор) не обязательно служит непосредственной мерой синтагматической длины. Этот чрезвычайно важный момент (к которому мы еще вернемся) не всегда подчеркивался в статистических исследованиях языка. 2.4.7. ДИАХРОНИЧЕСКИЕ ИМПЛИКАЦИИ * Поскольку язык развивается во времени и «эволюционирует», удовлетворяя изменяющиеся потребности общества, его можно рассматривать как гомеостатическую (или «саморегулирующуюся») систему; при этом состояние языка в каждый данный момент «регулируется» двумя противоположными принципами. Первый из них (иногда называемый принципом «наименьшего усилия») заключается в тенденции увеличить до предела эффективность системы (в том смысле, в каком слово «эффективность» толковалось выше); его действие заключается в приближении синтагматической длины слов и высказываний к теоретическому идеалу. Другой принцип заключается в «стремлении быть понятым»; он тормозит действие принципа «наименьшего усилия» путем введения избыточности на разных уровнях. Следует, таким образом, ожидать стремления сохранить, при изменяющихся условиях общения, обе тенденции в равновесии. Из того, что среднее количество шумов постоянно для разных языков и разных стадий развития одного языка, следует, что степень избыточности языка постоянна. К несчастью, нельзя (по крайней мере в настоящее время) проверить гипотезу о том, что языки сохраняют оба названных противоположных принципа в «гомеостатичееком равновесии». (Мы рассмотрим этот вопрос ниже.) Тем не менее эта гипотеза является многообещающей. Ее вероятность поддерживается «законом Ципфа», а также тенденцией (отмеченной задолго до начала теоретико-информационной эры) к замене слов более длинными (и более «яркими») синонимами, особенно в разговорном языке, в тех случаях, когда частое употребление тех или иных слов лишает их «силы» (снижая их информационное содержание). Крайняя быстрота смены жаргонных выражений объясняется именно этим. Так же можно объяснить явление «омонимического конфликта» и его диахроническое разрешение (с большой полнотой проиллюстрированное Жильероном и его последователями). «Омонимический конфликт» может возникнуть тогда, когда принцип «наименьшего усилия», действуя совместно с другими факторами, обусловливающими звуковые изменения, приводит к снижению или уничтожению «запаса прочности», необходимого для различения субстанциальных реализаций двух слов, и таким образом к образованию омонимии. (Термин «омонимия» в наши дни обычно употребляется и по отношению к омофонии, и по отношению к омографии; ср. § 1.4.2. В данном случае имеется в виду, конечно, омофония.) Если омонимы более или менее равновероятны в большом числе контекстов, «конфликт» обычно разрешается путем замены одного из этих слов. Хорошо известным примером служит исчезновение в современном английском литературном языке слова quean (первоначально означавшего 'женщина', а затем — 'распутница' или 'проститутка'), которое вступило в «конфликт» со словом queen 'королева' в результате утраты существовавшего ранее различия между гласными, представленными орфографически как еа и ее. Наиболее известным из специальной литературы примером омонимического конфликта является, вероятно, случай со словами, означающими 'кот' и 'петух' в диалектах юго-западной Франции. Различавшиеся как cattus и gallus в латинском языке, оба слова в результате звуковых изменений слились в [gat]. «Конфликт» был разрешен путем замены слова [gat] = 'петух' различными другими словами, в том числе местными вариантами слов faisan ('фазан') или vicaire ('викарий'). Использование второго из них, по-видимому, основано на уже существовавшей ранее в «жаргонном» употреблении связи между 'петухом' и 'викарием'. Теме «омонимия» посвящена весьма богатая литература (см. библиографию в конце книги). 2.4.8. УСЛОВНЫЕ ВЕРОЯТНОСТИ ПОЯВЛЕНИЯ Как мы видели, появление отдельной единицы (звука или буквы, единицы выражения, слова и т. п.) может быть полностью или частично детерминировано контекстом. Теперь мы должны внести ясность в понятие контекстуальной детерминированности (или обусловленности) и вывести те импликации, которые оно имеет для лингвистической теории. Для простоты мы сначала ограничим свое внимание рассмотрением контекстуальной детерминированности, действующей в пределах синтагматически связанных единиц одного уровня языковой структуры; другими словами, мы в данный момент пренебрежем тем очень важным моментом, что комплексы единиц низшего уровня реализуют единицы высшего уровня, которые сами имеют контекстуально детерминированные вероятности. Мы будем употреблять символы х и у как переменные, каждая из которых обозначает отдельную единицу или синтагматически связанную группу единиц; кроме того, мы допустим, что х и у сами находятся в синтагматической связи. (Например, на уровне единиц выражения х может обозначать /b/ или /b/ + /i/, а у — /t/ или /i/ + /t/; на уровне слов х может обозначать men 'мужчины' или old 'старые' + men, а у — sing 'петь' или sing + beautifully 'прекрасно'.) Как х, так и у имеют среднюю a priori вероятность появления — рх и ру соответственно. Подобным образом сочетание х + у имеет среднюю вероятность появления, которую мы обозначим как pху. В предельном случае статистической независимости между х и у вероятность сочетания х + у будет равна произведению вероятностей х и у: рху = рх ? ру. Этот фундаментальный принцип теории вероятности можно проиллюстрировать посредством простого числового примера. Рассмотрим числа от 10 до 39 (включительно) и обозначим через х и у цифры 2 и 7 в первой и второй позиции их десятичного представления: сочетание x и у будет, таким образом, обозначать число 27. В пределах рассматриваемого ряда чисел (исходя из предположения, что все 30 чисел равновероятны) рх = 1/3 и py = 1/10. Если бы мы «задумали число между 10 и 39» и попросили бы кого-нибудь отгадать задуманное число, его шанс угадать правильно (без помощи другой информации) был бы один из тридцати: рхy = 1/30. Но допустим, что мы сказали ему, что это число кратно 3. Ясно, что его шанс правильно отгадать вырастает до 1/10. С нашей точки зрения, более существенно (поскольку мы рассматриваем вероятность появления одного знака в контексте другого) то, что выбор одного из двух знаков не является больше статистически независимым от выбора другого. Вероятность у, если дано, что х = 2, равна 1/3, поскольку только три числа кратны 3 в данном ряду (21, 24, 27); а вероятность x, если дано, что у = 7, равна 1, поскольку только одно число в пределах данного ряда оканчивается на 7 и кратно 3. Можно обозначить эти равенства как py (x) = 1/3 и рх (у) = 1. Условная вероятность появления у в контексте х равна 1/3, а условная вероятность х при данном у равна 1. (Два выражения «в контексте» и «при данном» следует понимать как эквивалентные; оба употребительны в работах по статистической лингвистике.) Обобщая этот пример: если рх (у) = рх (то есть если вероятность х в контексте у равна его априорной, необусловленной, вероятности), то х является статистически независимым от у; если же вероятность появления х увеличивается или уменьшается с появлением у, то есть если рх (у) > рх или рх (у) > рх, то х «положительно» или «отрицательно» обусловлен у. Крайним случаем «положительной» обусловленности является, конечно, полная избыточность при рх (у) = 1 (у предполагает х), а крайним случаем «отрицательной» обусловленности — «невозможность», то есть рх (у) = 0 (у исключает х). Важно иметь в виду, что контекстуальная обусловленность может быть и «положительной» и «отрицательной» (в том смысле, в каком эти термины здесь употребляются), а также что вероятность х при данном у не всегда, а точнее, лишь в редких случаях, равна вероятности у при данном х. Необходимым условием того, чтобы результаты какого бы то ни было статистического исследования представляли интерес для лингвистики, является разграничение между различными видами обусловленности. Как мы видели выше, синтагматические отношения могут быть линейными или нелинейными; поэтому и обусловленность может быть линейной или нелинейной. Если х и у линейно связаны, то при любой рх (у) мы имеем дело с прогрессивной обусловленностью в тех случаях, когда у предшествует х, и с регрессивной в тех случаях, когда у следует за х. Независимо от того, является ли обусловленность прогрессивной или регрессивной, х и у могут непосредственно соседствовать (находиться рядом в линейно упорядоченном синтагматическом комплексе); в этом случае, если х обусловлен у, мы говорим о переходной (transitional) обусловленности. Многие популярные описания статистической структуры языка склонны изображать дело так, будто условные вероятности, действующие на всех уровнях языковой структуры, непременно предполагают линейную, переходную и прогрессивную обусловленность. Это, разуме ется, не так. Например, условная вероятность появления определенного существительного в качестве субъекта или объекта при определенном глаголе в латыни не зависит от относительного порядка, с каким слова встречаются во временной последовательности (ср. § 2.3.5); употребление префиксов un- и in- в английском языке (в таких словах, как unchanging 'неизменный' и invariable 'неизменный') регрессивно обусловлено; возможность появления определенной единицы выражения в начале слова может быть «положительно» или «отрицательно» обусловлена наличием некоторой единицы выражения в конце слова (или наоборот) и т. д. Конечно, в принципе можно подсчитать условную вероятность любой единицы относительно любого контекста. Существенно, однако, правильно выбрать контекст и направление обусловленности (то есть, скажем, подсчитывать рх (у), а не рy (x)) в свете того, что уже известно об общей синтагматической структуре языка. (Определенный класс единиц X может предполагать или допускать появление единиц другого, синтагматически связанного с ним класса Y на определенном по отношению к нему месте (и может также исключать возможность появления единиц третьего класса Z). При условии, что это так, можно подсчитать условную вероятность отдельного члена класса Y). Результаты будут иметь статистический интерес тогда, и только тогда, когда рх (у) или рy (x) будут существенно отличаться от рх и рy. 2.4.9. ПОЗИЦИОННЫЕ ВЕРОЯТНОСТИ АНГЛИЙСКИХ СОГЛАСНЫХ * Вероятности можно также подсчитывать для отдельных структурных позиций. Например, в таблице 4 для каждого из 12 согласных устной английской речи приводятся 3 ряда вероятностей: (i) априорная вероятность, средняя для всех позиций; (ii) вероятность в позиции начала слова перед гласными; (iii) вероятность в позиции конца слова после гласных. Таблица 4 Вероятности некоторых английских согласных в различных позициях в слове
Можно заметить существенные различия частотностей отдельных согласных в разных позициях в слове. Например, из перечисленных единиц [v] — наименее частая в позиции начала слова, но третья по частотности в позиции конца слова; с другой стороны, [b] — третья по частотности единица в начальной позиции слова, но наименее частая в позиции конца слова (за исключением [h], который вообще не встречается на конце. NB: мы говорим о звуках, а не буквах). Другие (как [t]) имеют высокую вероятность или (как [g] и [р]) низкую вероятность для обеих позиций. Также заметим, что диапазон колебаний между наивысшей и наименьшей вероятностью больше для конца слова, чем для начала. Факты этого рода получают отражение в описании статистической структуры фонологических слов английского языка. Выше мы говорили (в связи с «законом Ципфа»; см. § 2.4.6), что число звуков или букв в слове не является непосредственной мерой его синтагматической длины, определяемой в терминах теории информации. Причина этого, конечно, в том, что не все звуки или буквы равновероятны в одном контексте. Если бы вероятность фонологического или орфографического слова была прямо связана с вероятностями составляющих его элементов выражения, можно было бы получить вероятность слова перемножением вероятностей элементов выражения для каждой структурной позиции в слове. Например, если х в два раза вероятнее у в начальной позиции, а а вдвое вероятнее b в конечной позиции, можно ожидать, что хра будет встречаться в два раза чаще, чем yra или xpb, и в четыре раза чаще, чем ypb. Но это предположение не оправдывается в конкретных случаях, что ясно из рассмотрения нескольких английских слов. Элементы выражения, реализуемые посредством [k] и [f], более или менее равновероятны в начале слова, но слово call встречается намного чаще, чем fall (как показывают различные опубликованные частотные списки для английских слов); хотя элемент, реализуемый посредством [t], имеет вероятность появления в конечной позиции слова почти в 50 раз большую, чем вероятность элемента, реализуемого посредством [g], слово big встречается примерно в 4 раза чаще, чем bit, и т. д. Вероятности для начальной и конечной позиций, используемые для этих расчетов (см. табл. 4), основаны на анализе связного текста. Это означает, что частота появления определенного согласного, встречающегося в относительно небольшом количестве высокочастотных слов, может превысить частоту появления другого согласного, встречающегося в очень большом количестве низкочастотных слов (ср. замечания, сделанные в § 2.4.1 в связи с понятием «функциональной нагрузки»). Согласный [?], который встречается в начале таких английских слов, как the, then, their, them и т. д., иллюстрирует эффект такого перевеса. В начальной позиции это наиболее частый из всех согласных с вероятностью около 0,10 (ср. вероятность 0,072 для [t], 0,046 для [k] и т. д.). Но этот согласный встречается только в горсточке разных слов (менее чем в тридцати в современном языке). Напротив, начальное [k] мы находим во многих сотнях разных слов, хотя вероятность его появления в связном тексте более чем в два раза меньше, чем вероятность появления [?]. Сравнение всех английских слов, реализуемых как согласный + гласный + согласный (что само по себе является весьма обычной структурой для английских фонологических слов), показывает, что вообще существует больше слов с высокочастотным начальным и конечным согласным, чем слов с низкочастотным начальным и конечным согласным, и что первые к тому же обычно имеют большую частоту появления. В то же время следует подчеркнуть, что некоторые слова значительно более частотны или значительно менее частотны, чем можно было бы предсказать, исходя из вероятностей составляющих их элементов выражения. 2.4.10. «СЛОИ» ОБУСЛОВЛЕННОСТИ Хотя до сих пор мы рассматривали вопрос о контекстуальной детерминированности по отношению к условным вероятностям, существующим среди единиц одного уровня, ясно, что появление того или иного элемента выражения в весьма значительной степени определяется контекстуальной вероятностью фонологического слова, в которое он входит. Например, каждое из трех слов, записываемых как book, look и took, характеризуется частой встречаемостью: они отличаются друг от друга фонологически (и орфографически) только начальным согласным. С точки зрения грамматической структуры английского языка вероятность контраста между этими тремя словами в реальных высказываниях относительно мала (и совершенно не связана с вероятностями начальных согласных). Слово took отличается от двух других в ряде отношений, прежде всего тем, что оно реализует прошедшее время глагола. Поэтому оно более свободно, чем look и book, появляется рядом с такими словами и словосочетаниями, как yesterday 'вчера' или last year 'в прошлом году' (для look и book фонологические слова, соответствующие took, — это слова, записываемые как looked и booked); далее, в качестве подлежащего при took может выступать he 'он', she 'она' или it 'оно' или существительное в единственном числе (he took 'он взял' и т. п., но не he look или he book и т. п.); и, наконец, оно не может встречаться после to (например, I am going to took неприемлемо). Но слова book и look также отличаются друг от друга грамматически. Каждое из них может быть употреблено как существительное или глагол в соответствующем контексте (следует помнить, что фонологическое слово может быть реализацией более чем одного грамматического слова; см. § 2.2.11). Хотя look гораздо чаще встречается как глагол ('смотреть'), a book — как существительное ('книга'), это различие менее существенно по сравнению с такими грамматическими фактами не статистической природы, как то, что в качестве глагола слово book (то есть 'заказать' и т. п.), в отличие от look, может иметь при себе существительное или именное словосочетание в функции прямого дополнения (I will book my seat 'Я закажу место', Не is going to book my friend for speeding 'Он собирается привлечь к ответственности моего друга за превышение скорости'; слово look здесь невозможно); look же обычно требует «предложного сочетания» (I will look into the matter 'Я рассмотрю [этот] предмет'; букв, 'я буду смотреть в [этот] предмет', They never look at me 'Они никогда не смотрят на меня'; слово book здесь невозможно). По-видимому, в большинстве английских высказываний, произносимых говорящими в повседневной речи, смешение слов book и look исключается в силу грамматических ограничений того или иного рода. И это совершенно типично для минимально-контрастирующих фонологических слов в английском языке. Но рассмотрим теперь относительно небольшое множество высказываний, в которых как book, так и look грамматически приемлемы. Носителю английского языка совсем не трудно представить себе такие высказывания; при случае они могут быть произведены или услышаны. Примером могло бы служить I looked for the theatre 'Я искал театр': I booked for the theatre 'Я резервировал место в театре'. Можно допустить, в интересах доказательства, что слушающему было «передано» в этих высказываниях, без значительных искажений из-за «шумов» в «канале», все, за исключением начальных согласных слов booked или looked. В этом случае слушающий столкнется с необходимостью предсказать, основываясь на избыточностях в языке и учитывая ситуацию высказывания, которое из двух слов имел в виду говорящий. (Для простоты предположим, что cooked 'стряпал' и т. п. невозможны или весьма маловероятны в данной ситуации.) Хотя можно предположить, что looked встречается намного чаще, чем booked, в любой представительной выборке английских высказываний, однако нам совершенно ясно, что появление theatre значительно повышает вероятность слова booked. Очень трудно сказать, какое из слов — booked или looked — вероятнее в сочетании с for the theatre, но в той или иной конкретной ситуации выбор одного из них может оказаться детерминированным в большей степени, нежели другого. Это очевидно из сопоставления следующих двух, более длинных высказываний: (i) I looked for the theatre, but I couldn't find it. 'Я искал театр, но не нашел его'. (ii) I booked for the theatre, but I lost the tickets. 'Я резервировал место в театре, но потерял билеты'. Слово booked, по-видимому, контекстуально исключено в (i), а looked — в (ii). Однако и сама ситуация, включающая предшествующий разговор, может также вводить разнообразные «пресуппозиции», детерминирующая сила которых не ниже, чем у слов but и couldn't find в (i) и but и tickets в (ii). Если это так, то эти пресуппозиции уже «обусловят» то, что слушающий «предскажет» (то есть, собственно говоря, услышит) looked, а не booked (или наоборот) в более коротком «обрамлении» I -ooked for the theatre. Пока что можно обозначить эти вероятности, выводимые из совместного появления одного слова с другим и «пресуппозиций» конкретной ситуации высказывания, как «семантические». (В последующих главах мы выделим различные уровни приемлемости внутри того, что здесь мы относим к «семантике».) Наш пример был сильно упрощен: мы выделили только три уровня обусловленности (фонологический, грамматический и семантический) и исходили из того, что только одна единица выражения теряется, или искажается, из-за «шумов». Эти упрощения, однако, не затрагивают общего вывода. Если обратиться к рассмотрению конкретных высказываний, это приведет к признанию того, что семантические вероятности важнее грамматических, а грамматические важнее фонологических. Поскольку невозможно (по крайней мере при настоящем состоянии лингвистических исследований) выделить все семантически релевантные факторы внешних ситуаций, в которых фигурируют отдельные высказывания, оказывается также невозможным подсчитать вероятность, а потому и информационное содержание какой-либо их части. Это один из моментов, который уже подчеркивался нами, когда речь шла о функциональной нагрузке и теории информации (см. § 2.4.1). 2.4.11. МЕТОДОЛОГИЧЕСКОЕ РАЗРЕШЕНИЕ ОДНОЙ ДИЛЕММЫ В этом разделе были выдвинуты два положения, на первый взгляд противоречащие одно другому. Согласно первому, статистические соображения существенны для понимания механизма функционирования и развития языка; согласно второму, практически (а быть может, и принципиально) невозможно точно подсчитать количество информации, которую несут различные языковые единицы в конкретных высказываниях. Это видимое противоречие можно разрешить путем признания того, что лингвистическая теория не занимается тем, как производятся и понимаются высказывания в реальных ситуациях их употребления (если оставить в стороне относительно небольшой класс языковых высказываний, о которых будет идти речь в § 5.2.5); она занимается структурой предложений, рассматриваемых в отвлечении от ситуаций, в которых встречаются реальные высказывания. Примечания:2 R. Н. Rоbins. The Teaehing of linguistics as a part of a university tea-ching today. — «Folia Linguistica», 1976, Tomus IX, N 1/4, p. 11. 24 В переводе глав 2—6 участвовал А. Д. Шмелев. — Прим. редакции. 25 В оригинале термину «словосочетание» соответствует термин «фраза» (phrase). В британской лингвистической традиции под термином «фраза» разумеется любая группа слов (например, the table), функционирующая как слово. Об этом см. ниже, в § 5.1.1. — Прим. ред. 26 В советской науке более принято относить математическую лингвистику к математическим дисциплинам. Это, разумеется, отнюдь не препятствует использованию математического аппарата (и в частности, математической логики) в лингвистических исследованиях. — Прим. ред. 27 Видимо, опечатка; следует читать (i). — Прим. перев. 28 В оригинале, вероятно, ошибочно — минимальное. — Прим. перев. 29 Употребление to в пропущенных местах предложений I want to go home 'Я хочу пойти домой', I asked him to help me 'Я попросил его помочь мне' является обязательным правилом английской грамматики. — Прим. перев. |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||