|
||||
|
|
4.2.10. ВЫДЕЛЕНИЕ ПОДКЛАССОВ (СУБКЛАССИФИКАЦИЯ) 4. Грамматика: общие принципы 4.1. ВВОДНЫЕ ЗАМЕЧАНИЯ 4.1.1. «ГРАММАТИКА» Термин «грамматика» (полученный нами через посредство французского и латинского языков) восходит к греческому слову, которое можно перевести как 'искусство письма'. Но еще на заре истории греческой науки это слово приобрело более широкий смысл и стало охватывать все изучение языка, предпринимаемое в рамках греческой традиции. История лингвистики на Западе до недавних пор — это в значительной мере история того, что ученые в разное время относили к сфере «грамматики» в этом, широком смысле. 4.1.2. ФЛЕКСИЯ И СИНТАКСИС Позднее термину «грамматика» было придано более узкое толкование. В настоящее время его употребление обычно ограничивается той частью языкового анализа, которая в классической грамматике обозначалась как флексия и синтаксис. Традиционное разграничение флексии и синтаксиса, которое связано с признанием отдельного слова основной единицей языка, можно сформулировать так: флексия, или словоизменение, относится к внутренней структуре слова, а синтаксис описывает способы, посредством которых слова соединяются в предложения. Пока мы не будем стремиться к точным определениям понятий «слово» и «предложение». Будем считать, что грамматика представляет правила, в соответствии с которыми слова сочетаются друг с другом, образуя предложения. Таким образом, из сферы грамматики исключается, с одной стороны, фонологическое описание слов и предложений и, с другой стороны, описание значения отдельных слов и предложений. Можно заметить, что когда нелингвист называет какое-то сочетание слов или форму отдельного слова «грамматически правильным» или «грамматически неправильным» («grammatical» или «ungrammatical»), он имеет в виду именно данное понимание грамматики. 4.1.3. «ПОНЯТИЙНАЯ» ГРАММАТИКА * Современную лингвистическую теорию нередко называют «формальной» в противоположность традиционной грамматике, которую называют «понятийной». По словам Есперсена, выдающегося представителя старшего поколения грамматистов, концепция которого стоит между традиционным и современным подходом к грамматическому анализу, «понятийная» грамматика исходит из наличия «внеязыковых категорий, не зависящих от более или менее случайных фактов существующих языков»; эти категории «универсальны, поскольку они применимы ко всем языкам, хотя они редко выражаются в этих языках ясным и недвусмысленным образом». Существуют ли универсальные грамматические «категории» в том смысле, в каком Есперсен и традиционные грамматики понимают этот термин, — это вопрос, который мы рассмотрим ниже. Пока мы допустим, что таких категорий нет (или по крайней мере может не быть); делая это допущение, мы встаем на позицию формального подхода к грамматике. Следует отметить, что это довольно-таки специфическое употребление термина «формальный», и оно не имеет никакого отношения к разграничению «формы» и «субстанции», проведенному выше (см. § 2.2.2). Оно также отличается от более обычного научного употребления, согласно которому формальной, или формализованной, называют теорию, в которой теоремы выводятся из основных понятий и аксиом путем применения эксплицитных правил вывода. Как мы увидим ниже, в последнее время лингвистика значительно продвинулась вперед по пути формализации грамматической теории в этом более общем смысле термина «формальный». Пока что условимся употреблять термин «формальный» в противовес понятийной концепции; таким образом, будем считать, что формальная грамматика не делает никаких допущений об универсальности таких, например, категорий, как «части речи» (в их традиционном определении), и пытается описать структуру каждого языка в его собственных терминах. Более определенная характеристика того содержания, которое вкладывалось лингвистами в противопоставление «формальный» — «понятийный», будет дана в следующем разделе. 4.1.4. СЕМАНТИЧЕСКИЕ СООБРАЖЕНИЯ В ГРАММАТИКЕ «Формальный» подход к грамматическому описанию нередко отождествляли с представлением относительно несущественности семантических соображений как при выделении единиц грамматического анализа, так и при установлении правил их сочетаемости в предложениях данного языка. Действительно, многие весьма интересные и плодотворные результаты, достигнутые современной теорией грамматики, были связаны с идеей о принципиальной независимости теории и практики грамматического описания от значения. Однако часто ошибочно полагают, что лингвисты, которые отказываются допустить семантические соображения в грамматическую теорию, делают это потому, что не интересуются проблемами семантики. Это не так. Не следует также думать, что в основе упомянутой позиции лежит представление о большей субъективности семантического анализа по сравнению с фонологическим или грамматическим анализом. Причина только в том, что грамматическая и семантическая структура языка в значительной мере, но не полностью, конгруэнтны. Как только лингвист начинает серьезно интересоваться семантикой, он видит, что, отделяя в методических целях семантику от грамматики, он только выигрывает. Пока исходят из того, что каждому тождеству или различию в грамматической структуре должно отвечать соответствующее тождество или различие значения (пусть тонкое и трудно определимое), существует опасность исказить грамматическое описание, либо семантическое описание, или и то и другое. В этой связи следует также отметить, что методическое разделение грамматики и семантики касается только способа подачи лингвистического описания. Оно не означает, что лингвист намеренно отказывается использовать свое понимание значения предложений, когда он исследует их грамматическую структуру. Ниже мы увидим, что если какое-то предложение неоднозначно (имеет два или более значений), это часто указывает на то, что ему следует приписать две или более грамматические структуры (см. § 6.1.3). Но мы также увидим, что неоднозначность предложения сама по себе не является достаточным основанием для того, чтобы признать, что за ним скрываются различные грамматические структуры. 4.1.5. ТЕРМИН «ФОРМАЛЬНЫЙ» * То обстоятельство, что употребление в специальной литературе термина «формальный» (как и многих других терминов, используемых лингвистами) обнаруживает столь значительное разнообразие, разумеется, достойно сожаления. Было бы, вероятно, не так трудно избежать использования подобных многозначных терминов. Однако всякий, кто начинает заниматься лингвистикой, рано или поздно должен научиться понимать слова типа «формальный» в соответствии с контекстом, в котором они встречаются. Сделать это легче, если знать их историю. Поэтому мы будем часто останавливаться вкратце на этимологии или истории развития важнейших специальных терминов, когда будем рассматривать связанные с ними понятия. Что касается слова формальный, то необходимо иметь в виду, что оно обычно употребляется в следующих смыслах: (i) по отношению к фонологической и грамматической структуре языка, в противоположность термину семантический (в силу традиционного разграничения между «формой» слова и его «значением»; см. § 2.1.2); (ii) по отношению к фонологической, грамматической и семантической структуре языка, противополагаясь «средствам», которыми реализуется язык, то есть мыслительному или физическому континууму, «структурируемому» лексическими элементами языка (в этом смысле «формальное» противопоставлено «субстанциальному» в духе соссюровского разграничения «субстанции» и «формы»; см. § 2.2.2); (iii) как эквивалент «формализованного» или «эксплицитного», в противоположность «неформальному» или «интуитивному»; (iv) в противоположность «понятийному» в том смысле, который мы проиллюстрировали, употребив этот термин выше в цитате из Есперсена. Из этих четырех значений (i) и (iv) не всегда различаются в специальной литературе: говоря о «понятийной» грамматике, лингвисты обычно полагают, что любые универсальные категории, постулируемые грамматиками, непременно основаны на значении. (Обоснованно ли это предположение или нет, мы здесь обсуждать не будем; мы просто обращаем внимание на тот факт, что часто считают само собой разумеющимся то, что «понятийное» означает «основанное на значении».) Наиболее существенные недоразумения связаны, пожалуй, с толкованием (ii), находящимся в прямом противоречии с толкованием (i). Для полноты картины, возможно, следует упомянуть, что в новейшей литературе Хомским, при рассмотрении универсальных свойств языка, было введено несколько иное противопоставление. Оно состоит в разграничении «формальных» и «субстантных» универсалий (NB: «субстантных», а не «субстанциальных»). В самом общем плане это разграничение опирается на различие между характером правил, употребляемых лингвистом при описании языка, и элементами (лингвистическими единицами или классами единиц), фигурирующими в правилах. Если, например, принять, что имеется фиксированное множество дифференциальных признаков, определенный набор которых образует разные сочетания в фонологических системах отдельных языков (см. § 3.3.11), то можно считать, что эти дифференциальные признаки образуют субстантную универсалию фонологической теории. Напротив, любые условия, налагаемые на способ действия фонологических правил или сочетания фонологических единиц в соответствии с определенными правилами, составляют формальную универсалию фонологической теории. Постулат одномерности, например, можно рассматривать как формальную универсалию «ортодоксальной» фонематической теории (см. § 3.3.14). Использование Хомским термина «формальный» связано со значением (iii) предыдущего абзаца. Универсальные категории традиционной грамматики (в особенности «части речи») не могут быть описаны ни как формальные, ни как субстантные в строгом применении этого разграничения, так как правила традиционной грамматики не были эксплицитно формализованы. Однако, вероятно, справедливым будет сказать, вслед за Хомским, что они определены главным образом в «субстантных» терминах. Следует отметить, однако, что в традиционные определения «частей речи» нередко включается и некоторая характеристика их комбинаторных свойств. Мы вернемся к этому вопросу ниже (см. § 7.6.1 и сл.). Эти терминологические замечания предназначены в помощь тому читателю, который, возможно, читал или продолжает читать другие работы по лингвистической теории. В данной книге термин «формальный» употребляется в значениях (iii) и (iv), то есть противопоставляется «понятийному», с одной стороны, и «неформальному» — с другой; в настоящей главе мы будем по мере изложения переходить от одного значения к другому. В тех случаях, когда слово «форма» будет употребляться в специальном значении, его легко будет распознать по соседним терминам, то есть по соположению со «значением» либо с «субстанцией»; см. выше (i) и (ii). 4.2. ФОРМАЛЬНАЯ ГРАММАТИКА * 4.2.1. «ПРИЕМЛЕМОСТЬ» Мы должны теперь попытаться охарактеризовать современную грамматическую теорию несколько более определенно, чем мы это делали до сих пор. Начнем с того, что введем понятие «приемлемости». «Приемлемость» — это примитивный, донаучный термин, нейтральный по отношению к ряду разграничений, которые мы сделаем ниже, включая проводимое традиционно разграничение между «грамматичным» и «осмысленным» (или «значимым»). Это более примитивный термин, нежели «грамматичность» или «осмысленность», в том смысле, что в отличие от этих терминов он не зависит от каких бы то ни было специальных определений или теоретических представлений лингвистики. Приемлемым является высказывание, которое произведено или могло быть произведено носителем языка в некоторой подходящей обстановке и признается или было бы признано другими говорящими в качестве принадлежащего рассматриваемому языку. Задача лингвиста (хотя она этим и не исчерпывается) — определить возможно более простым способом приемлемые предложения описываемого языка и сделать это в терминах какой-то общей теории языковой структуры. Лингвист, описывающий современный язык, обычно имеет в своем распоряжении собрание записанных высказываний (его «данные», или «корпус»); он также имеет возможность обращаться к помощи носителей языка («информантов»). Разумеется, он и сам может выступать в роли информанта, если описывает собственный язык; но в этом случае он не должен произвольно ограничивать свой корпус только таким материалом, который будет включать лишь предложения, удовлетворяющие его предвзятым идеям относительно структуры языка. В процессе описания лингвист может получить от информантов различные новые высказывания и тем самым расширить корпус; он может проверить с ними приемлемость предложений, которые строит он сам, чтобы убедиться в общем характере выведенных им пробных правил. Если он обнаружит, что его информанты не считают естественным или нормальным предложением то или иное высказывание, удовлетворяющее установленным им к тому моменту правилам приемлемости, он должен, если возможно, переформулировать правила таким образом, чтобы они исключали данное «предложение», но сохраняли в качестве приемлемых предложения, для которых они в первую очередь были установлены. В случае так называемых «мертвых» языков, вроде латинского, верифицировать установленные правила, проверяя с носителями приемлемость всех предложений, описываемых этими правилами, естественно, невозможно. Поэтому описание того или иного классического языка неизбежно будет неполным в некоторых отношениях. Однако адекватность описания будет прямо пропорциональна количеству и разнообразию материала, на котором оно основано. С первого взгляда может показаться, что термин «приемлемость», как мы его здесь употребляли, избыточен и приводит к излишним осложнениям. Можно подумать, что сказать, что данное высказывание приемлемо, значит только сказать, что оно было произведено в тот или иной момент каким-нибудь носителем языка и что в принципе лингвист или группа лингвистов могут собрать все предложения языка и поместить их в корпус. Но этот взгляд ошибочен. Термин «приемлемость» имеет не только то преимущество, что он подчеркивает операционную связь между «сырым материалом» лингвиста и реакцией носителей языка как конечной контрольной инстанцией; он также подчеркивает тот факт, что лингвист должен описывать не только высказывания, действительно встретившиеся в прошлом, но и целый ряд других высказываний, которые могли бы встретиться в прошлом и могли бы появиться в будущем. Традиционные грамматики обычно исходили именно из такого взгляда и иногда выражали его эксплицитным образом. Позднее, желая избежать ловушек предписывающей грамматики (см. § 1.4.3), многие лингвисты заявляли, что их описания некоторого корпуса материала имеют силу только относительно предложений, действительно встречающихся в корпусе, и не содержат выводов относительно того, какие еще предложения могли бы быть произведены носителями рассматриваемого языка. Но эта позиция, какие бы благие цели при этом ни преследовались, как мы увидим, несостоятельна ни в теоретическом, ни в практическом плане. 4.2.2. КОЛИЧЕСТВО ПРЕДЛОЖЕНИЙ ЯЗЫКА МОЖЕТ БЫТЬ НЕОГРАНИЧЕННЫМ Любой носитель языка способен производить и понимать не только те предложения, которые он когда-то до этого слышал, но также бесконечно большое количество новых предложений, которых он никогда не слышал от других носителей языка. Можно даже утверждать, что большинство производимых носителями языка предложений, за исключением ограниченного набора ритуальных высказываний (типа How do you do? 'Здравствуйте!' или Thank you 'Спасибо' и т. п.), представляют собой «новые» предложения в этом смысле. И эти «новые» предложения будут удовлетворять тому же операционному испытанию на приемлемость для носителей, что и «старые» предложения, которые могут быть извлечены из памяти. Они обнаруживают те же закономерности и описываются теми же самыми правилами. Другими словами, с предложениями языка следует отождествить класс потенциальных высказываний. Число же потенциальных высказываний в любом естественном языке неограниченно. Любой данный набор высказываний, независимо от объема, представляет собой только «выборку» из этого неограниченного множества потенциальных высказываний. Если выборка не только большая, но отражает все множество потенциальных высказываний, она будет ex hypothesi обнаруживать все закономерности, характерные для строения языка в целом. (Сделанное здесь разграничение между «выборкой» и языком в целом, — это, в сущности, разграничение между «речью» и «языком», проведенное Соссюром; см. § 1.4.7.) Таким образом, задача лингвиста, описывающего язык, состоит в установлении правил, способных охарактеризовать бесконечно большое множество потенциальных высказываний, которые составляют язык. Любое лингвистическое описание, которое способно описать реальные высказывания как члены большого класса потенциальных высказываний, называется генеративным (дальнейшее рассмотрение этого термина см. в § 4.2.13). Мы увидим, что если установленные правила определяют приемлемость высказываний в пределах достаточно представительной выборки, то эти же правила неизбежно будут описывать гораздо большее множество высказываний, не принадлежащих исходному корпусу (при условии, что применение этих правил не будет очень сильно и «неестественно» ограничено). Больше того, если в описание будут включены правила с некоторыми специальными свойствами, оно будет способно охарактеризовать бесконечное, хотя и строго определенное множество приемлемых высказываний. Таким образом, генеративное описание отражает (и в определенном смысле «объясняет») способность носителя языка производить и понимать бесконечно большое множество потенциальных высказываний. 4.2.3. «УРОВНИ» ПРИЕМЛЕМОСТИ * Теперь перед нами встает следующий вопрос: в какой степени приемлемость (и какого рода приемлемость) входит в компетенцию грамматики, а в какой степени она оценивается другими частями лингвистического описания или нелингвистическими дисциплинами? Кажется очевидным, что высказывания могут быть приемлемыми или неприемлемыми в разных отношениях и в различной степени. Мы могли бы, например, сказать, что английский язык какого-нибудь иностранца «грамматически» приемлем (или правилен), но его «выговор» ошибочен и немедленно выдает его как человека, для которого английский не является родным. Мы могли бы сказать об определенных предложениях (как, например, Рассел о предложении Quadruplicity drinks procrastination), что они «грамматичны», но «бессмысленны»; то же самое, хотя по несколько иным причинам, мы могли бы сказать о стихах-бессмыслицах Льюиса Кэрролла. Существуют и другие виды приемлемости и неприемлемости, не имеющие ничего общего с тем, осмысленно лк высказывание или нет. В сказках и в научно-фантастической литературе содержится много примеров предложений, которые были бы неприемлемы в «повседневном» английском языке. С другой стороны, некоторые высказывания, хотя и осмысленные, рассматривались бы некоторыми людьми в определенных обстоятельствах как «кощунственные» или «непристойные»; это можно обозначить в общих чертах как «социальную приемлемость». 4.2.4. «ИДЕАЛИЗАЦИЯ» ДАННЫХ * Когда мы считаем, что два человека говорят на одном и том же языке, мы по необходимости отвлекаемся от всевозможных различий в их речи. Эти различия, отражающие разницу в возрасте, поле, принадлежности к разным социальным группам, образованности, культурных интересах и т. д., важны и должны, по крайней мере в принципе, учитываться лингвистом. Однако в речи любых людей, которые, как мы считаем, «говорят на одном и том же языке», будет нечто такое, что можно описать как «общее ядро» — значительное совпадение в словах, которые они употребляют, в способе сочетания этих слов в предложениях и в значении, которое они придают этим словам и предложениям. Возможность общения предполагает существование этого «общего ядра». Для простоты изложения допустим, что описываемый язык однороден (под «однородностью» понимается отсутствие различий по «диалектам и стилям»), что, конечно, представляет собой «идеализацию» фактов (ср. § 1.4.5), и что мнения всех носителей языка относительно того, приемлемо ли некоторое высказывание или нет, совпадают. Мы также предположим, что описание, предназначенное главным образом для «нормальных» высказываний, может быть расширено таким образом, чтобы быть приложимым к тем «странным» предложениям, которые встречаются в детских рассказах или в научно-фантастической литературе. Поэтому мы сосредоточимся на разграничении фонологической приемлемости и грамматической приемлемости, с одной стороны, и грамматической приемлемости (грамматичности) и семантической приемлемости (осмысленности) — с другой. 4.2.5. ФОНОЛОГИЧЕСКАЯ И ГРАММАТИЧЕСКАЯ ПРИЕМЛЕМОСТЬ * В предыдущем разделе мы видели, что каждый язык обладает собственной фонологической структурой, описываемой в терминах некоторого множества единиц (фонем или фонологических единиц различного рода, в зависимости от характера языка и модели анализа, принятой лингвистом) и правил их сочетаемости. Некоторая доля неприемлемости (включая большую часть того, что принято обозначать как «акцент») может быть описана на фонологическом или даже фонетическом уровне. Если бы мы задались целью получить множество последовательностей фонологических единиц, таких, что каждая последовательность была бы построена в соответствии с правилами сочетаемости, установленными посредством фонологического анализа рассматриваемого языка, мы обнаружили бы, что только бесконечно малая часть полученных «высказываний» приемлема для носителя языка. Этот момент легко проиллюстрировать на английском примере. Для простоты мы можем предположить, что английская орфография точно отражает фонологическую структуру языка. Хотя это предположение, конечно, ошибочно, оно не влияет на обоснованность иллюстрируемого утверждения. Возьмем в качестве примера следующее английское предложение: iwantapintofmilk 'Яхочу пинту молока'. (Оно напечатано без пробелов, чтобы указать, что в данный момент мы рассматриваем его просто как последовательность букв, каждая из которых изображает, как мы допустили, одну фонологическую единицу; конечно, в обычном произношении соответствующего устного высказывания пауз между словами нет.) Используя наше представление о допустимых последовательностях английских букв, мы можем попытаться заменять отдельные буквы и группы букв в разных местах нашего предложения. Мы знаем, например, что s может следовать за i и стоять перед а (ср. isangasongofsixpence 'Я спел песню шестипенсовика'); однако *isantapintofmilk не является приемлемым предложением. Здесь и в дальнейшем будем пользоваться звездочкой перед словом или предложением для обозначения их неприемлемости. В лингвистической практике такое применение данного символа получило широкое распространение. В историческом и сравнительном языкознании звездочка обычно обозначает незасвидетельствованное или «реконструированное» слово или фонологическую единицу (ср. § 1.3.13). Неприемлемы также *iwantapinkofrnilt или *ipindawantopfilk, хотя ни одно из этих высказываний не противоречит фонологической структуре английского языка. Даже если бы мы выявили на большом отрывке текста не только допустимые пары, тройки, четверки и т. д. букв, но также вероятности появления отдельных букв в соответствующем окружении (такие подсчеты были выполнены для английского и некоторых других языков, а результаты использовались для дешифровки и при разработке каналов связи для передачи письменных сообщений), это не помогло бы нам в наших попытках построить другие приемлемые английские предложения путем замены отдельных букв или групп букв в нашем предложении. Дело в том, что определенные «блоки» букв образуют в языке единицы «более высокого уровня», на границах которых вероятности появления отдельных букв друг по отношению к другу не имеют большого значения для определения того, какие «блоки» могут сочетаться между собой, образуя приемлемые высказывания. Более существенным, нежели общая вероятность появления w после i и перед а, является тот факт, что w составляет часть «блока» want. С одной точки зрения блок можно рассматривать как допустимую для английского языка последовательность букв; с другой точки зрения его следует рассматривать как целостную единицу, которую могут заменять другие блоки букв, так, что при этом будут получаться приемлемые высказывания: idrinkapintofmilk 'Я пью пинту молока', itakeapintofmilk 'Я беру пинту молока' и т. п. При этом i 'я' также является «блоком»; то, что он состоит только из одной буквы, не существенно. На его место в данное окружение не может быть поставлена никакая другая отдельная буква так, чтобы получилось приемлемое высказывание, а только другие «блоки», например: 'we' мы, they 'они', thejoneses 'Джонсы' и т. п. То, что мы назвали «блоками», можно, по крайней мере в предварительном порядке, идентифицировать со словами языка. (Для упрощения мы не учитываем тот факт, что некоторые «блоки», которые могли бы заменить I в данном примере, являются не отдельными словами, а сочетаниями слов, например: The Joneses, They all 'они все' и т. п. Здесь читатель может вновь обратиться к разделу, в котором рассматривается «двойное членение» в плане выражения; см. §2.1.3). 4.2.6. ДИСТРИБУЦИОННЫЙ ПОДХОД К ГРАММАТИЧЕСКОМУ ОПИСАНИЮ Заметим, что мы пришли к традиционной точке зрения, согласно которой английские предложения «структурируются» на двух уровнях: на уровне букв (или фонологических единиц) и на уровне слов, не прибегая явным образом к понятию значения. Мы только отделили фонологический (или орфографический) компонент приемлемости от приемлемости иного рода с тем, чтобы выделить внутри этого «остатка» различные компоненты приемлемости «более высокого уровня». Конечно, верно, что высказывания I want a pint of milk; I drink a pint of milk и т. д. (теперь мы можем ввести промежутки между словами) осмысленны в соответствующем контексте. Кроме того, они различаются по своему значению; это различие значений высказываний уместно описывать как функцию от значений составляющих их слов want, drink и т. д. Но пока мы не учитывали эти факты; и мы не будем этого делать в пределах представленной здесь теории грамматики. Эти факты подлежат рассмотрению в теории семантики. В принципе мы только построили множество приемлемых предложений, помещая разные слова в одну и ту же «раму», или контекст. Все множество контекстов, в которых может встречаться лингвистическая единица, составляет ее дистрибуцию (см. §2.3.1). Таким образом, здесь излагался дистрибуционный подход к грамматическому анализу. Теперь мы можем констатировать, что фонология описывает приемлемость и неприемлемость высказываний в той мере, в какой это возможно, посредством правил или формул, устанавливающих допустимые сочетания фонологических единиц исследуемого языка, а описание приемлемости в терминах допустимых сочетаний слов на «более высоком» уровне как бы «переходит» к грамматике. 4.2.7. ВЗАИМОЗАВИСИМОСТЬ ФОНОЛОГИИ И ГРАММАТИКИ На этой стадии изложения следует подчеркнуть, что мы все еще исходим из предположения, что предложения состоят из слов, а слова состоят из фонологических единиц (или букв, если мы имеем дело с письменным языком). Оба этих предположения ниже будут видоизменены. (Обоснование стало бы несколько более сложным, но не потеряло бы силы, если бы мы уточнили их и теперь.) Следует также упомянуть, что, хотя из нашего изложения могло сложиться впечатление, будто грамматическое описание, будучи независимым от фонологического анализа, все же непременно следует за ним, это не обязательно должно быть так (ср. § 3.3.16). Мы устанавливаем грамматику и фонологию как теоретически различные уровни лингвистической структуры. Но фонологическая и грамматическая структура конкретных языков обычно взаимосвязаны (различным образом и в различной степени). В задачу лингвиста, описывающего тот или иной язык, входит объяснение этой взаимосвязи — там, где она имеется (наряду с объяснением возможной взаимозависимости между грамматической и семантической структурой языка). 4.2.8. ПРОСТОЙ ПРИМЕР ДИСТРИБУЦИОННОГО АНАЛИЗА Мы еще далеки от того, чтобы прийти к удовлетворительному представлению о лингвистическом описании. Мы еще не сказали, в частности, как определяются приемлемые сочетания слов. Перечисление списком всех приемлемых последовательностей слов совершенно невозможно, поскольку, как мы видели, ни один естественный язык нельзя рассматривать как ограниченное множество предложений. В случае замкнутого корпуса материала можно было бы, конечно, составить список всех фонологически (или орфографически) различных предложений и затем решать вопрос о приемлемости, справляясь в этом списке. Но это было бы малоинтересно в том смысле, что ничего не давало бы для нашего понимания способности носителя языка производить «новые» предложения; это не было бы к тому же и самым экономным способом описать данный текст. Если продолжить рассмотрение этого вопроса, мы поймем, по какой причине. В достаточно большой и представительной выборке из предложений какого-либо языка дистрибуции разных слов будут в значительной мере совпадать. Например, вместо milk 'молоко' можно поставить beer 'пиво', water 'вода', gin 'джин' и т. п. не только в I drink a pint of milk; этот же ряд слов мог бы появиться и во многих других окружениях, в которых может встретиться milk. Аналогично, слова they 'они', we 'мы' и you 'вы' могут заменить I 'я', a buy 'покупать', take 'брать', order 'заказывать' и т. д. могут заменить drink 'пить' во многих других окружениях, кроме нашего предложения. Слова, которые, как правило, способны заменять друг друга в целом ряде различных предложений, можно сгруппировать на этом основании в дистрибуционные классы. Допустим, что нам необходимо проанализировать корпус материала, состоящий из следующих 17 «предложений»: ab, ar, pr, qab, dpb, aca, pca, pcp, qar, daca, qaca, dacp, dacqa, dacdp, qpcda, acqp, acdp. Разными буквами обозначены разные слова: условная запись используется из соображений общности, а также чтобы пояснить, что на данном этапе мы обходимся без непосредственного привлечения семантики. (Впрочем, это может вызвать известные сомнения, поскольку мы исходим из того, что приемлемость сохраняется при операции замены, а понятие «приемлемости» включает «осмысленность». Мы, однако, стремимся разграничить «грамматическую правильность» и «осмысленность», хотя еще не достигли этого.) Мы видим, что а и р имеют некоторые общие окружения (ср. -r, pc-, dac-), так же как b и r (ср. a-, qa-) и d и q (ср. dac-a, -аса, ас-р), но что с имеет уникальную дистрибуцию (а-а, р-а, р-р, qa-a, da-a, da-p и т. д.) в том смысле, что ни в одном окружении, в котором встречается с, не встречается никакое другое слово. Теперь поместим а и р в класс X и поставим классный показатель X всюду, где встретятся а или р (предложения, которые отличаются только тем, что в одном из них представлено а, там, где в другом представлено р, будут сведены нашими формулами в один класс предложений): Xb, Xr (ar, pr), qXb, dXb, ХсХ (аса, рса, рср), qXr, qXcX, dXcX (daca, dacp), dxcqX, dXcdX, qXcdX, XcqX, XcdX. Теперь сгруппируем b и r в дистрибуционный класс Y, a d и q — в класс Z. Подставив Y вместо b и r, a Z вместо d и q, получим: (1) XY (Хb, Xr); (2) ZXY (qXb, qXr, dXb); (3) ХсХ; (4) ZXcX (qXcX, dXcX); (5) ZXcZX (dXcqX, dXcdX, qXcdX); (6) XcZX (XcqX, XcdX). Таким образом, мы можем описать предложения нашего корпуса в терминах шести структурных формул, определяющих приемлемые последовательности классов слов (с является одноэлементным классом). Эти формулы являются линейными (в смысле, который мы поясним ниже; см. §6.1.1). Пока мы можем удовлетвориться описанием предложений нашего корпуса в терминах их линейной структуры, то есть на языке следующих формул или правил: (1) XY (2) ZXY (3) XcX (4) ZXcX (5) ZXcZX (6) XcZX. Можно считать, что каждое из этих правил описывает отдельный тип предложения. (Тот факт, что можно свести эти типы предложений к подтипам, привлекая принципы структуры составляющих, не релевантен на данном этапе изложения; см. § 6.1.2 и сл.) Заметим, что эта система правил удовлетворительно объясняет приемлемость семнадцати предложений корпуса (она определяет их как грамматичные). Но это достигается только путем включения имеющихся предложений в общее множество из 48 предложений в качестве его элементов. (Число 48 получается после применения формулы, приведенной в § 2.3.8, к каждому из шести типов предложения и суммирования результатов.) Имеется 2 ? 2 = 4 предложения типа (1), 2 ? 2 ? 2 = 8 предложений типа (2), 2 ? 1 ? 2 = 4 предложения типа (3), 16 предложений типа (4), 8 — типа (5) и 8 — типа (6). 4 + 8 + 4 + 16 + 8 + 8 = 48. Поэтому язык, описываемый такой грамматикой, содержит ровно 48 предложений. Тридцать одно не встречающееся предложение можно допустить в качестве приемлемых или исключить, если мы почему-либо решим, что они должны быть исключены посредством дополнительных правил, запрещающих определенные сочетания отдельных слов. Дополнительные правила, очевидно, весьма усложнят «грамматику». Следовательно, наиболее экономным способом описания данного текста будет такой, который представит его как случайную выборку из 17 предложений, являющихся подмножеством общего множества из 48 предложений, которые и составляют язык. «Грамматика», построенная нами для описания этого текста, является генеративной в описанном выше смысле (см. § 4.2.2). Мы будем говорить, что она порождает, или характеризует, язык текста, приписывая каждому из имеющихся в «выборке» предложений (так же как и тем, которых нет в «выборке») особое структурное описание: pr — это предложение структуры XY, pcda — структуры XcZX и т. д. Этот ограниченный искусственный язык, использованный нами в качестве примера, содержит всего семь слов, а корпус включает лишь семнадцать простых предложений (из сорока восьми, порождаемых грамматикой). В случае естественных языков ситуация, без сомнения, оказывается значительно более сложной. Число слов выражается в десятках тысяч; их дистрибуционная классификация будет не столь простой и, несомненно, не сможет быть осуществлена только что проиллюстрированным способом. Кроме того, нам придется описывать целый ряд различных типов предложений, в том числе предложения значительной степени сложности. Однако эти факты не затрагивают самого принципа. Слова естественного языка могут быть сгруппированы в дистрибуционные классы (что всегда и делалось составителями грамматик на практике, как мы увидим ниже); дистрибуционные классы, установленные для конкретных позиций в предложениях одного типа, оказываются обычно действительными и для конкретных позиций в других, более сложных типах предложений. Грамматика, как она здесь понимается, есть не что иное, как описание предложений языка в терминах сочетаемостных свойств слов (а также словосочетаний и т. д.), определяемых их принадлежностью к тому или иному дистрибуционному классу. Это род алгебры, в которой в качестве «переменных» выступают словесные классы, а в качестве «постоянных», или «значений», принимаемых этими переменными в конкретных предложениях, — индивидуальные слова. Чтобы понять, что речь идет в принципе о такого рода описании, которое обычно называется «грамматическим», нам достаточно интерпретировать приведенный выше пример применительно к английскому языку. Пусть a = men 'мужчины', р = women 'женщины', b = live 'живут', r = die 'умирают', c = love 'любят', d = old 'старый (~ые, ~ых)', q = young 'молодой (~ые, ~ых)'. Другими словами, пусть класс X включает все те слова, которые обычно обозначаются как 'существительные во множественном числе'; пусть Y символизирует класс «непереходных глаголов», с — класс «переходных глаголов» и Z — класс «прилагательных». Наше утверждение о допустимых сочетаниях классов слов означает, что такие предложения, как Men die, Old men love young women и т. д., которые описывались традиционной грамматикой как случаи «субъектно-предикатной» конструкции, грамматически приемлемы, тогда как *Die men или *Old love young men women и т.п. неприемлемы. 4.2.9. ГРАММАТИЧЕСКИЕ КЛАССЫ В традиционной грамматической теории «части речи» (существительные, глаголы, прилагательные и т. д.) определялись — явным образом — в «понятийных» терминах («существительное — это название лица, места или вещи» и т. п.). Но, как мы увидим ниже (см. § 7.6.1 и сл.), рассматривая «части речи», традиционные грамматики нередко смешивали две различные проблемы. Первая, которая нас здесь и занимает, — это вопрос об определении условий, при которых можно считать, что данное слово принадлежит к тому или иному грамматическому классу: «Является ли слово men членом класса X или же класса Y?» На деле это всегда определялось на основе дистрибуции слова — возможности его встречаемости в предложениях в связи с наличием в тех же предложениях других слов. В этом смысле современная лингвистика лишь признала в грамматической теории дистрибуционный принцип, которым традиционные грамматики всегда руководствовались' на практике. Таким образом, «формальная» грамматика отличается от «понятийной» теоретическим признанием указанного принципа. Вторая проблема имеет отношение к наименованию грамматических классов (установленных — что касается составляющих их элементов — на «формальной» основе): «Уместно ли называть X классом «существительных»?» С точки зрения «формальной» грамматики, всякое обозначение так же хорошо, как и любое другое; и традиционные термины «существительное», «глагол», «прилагательное» и т. д. не более и не менее удовлетворяют этой цели, чем любые другие термины. Ниже мы увидим, что возможно определить такие термины, как «существительное» или «глагол», способом, который будет учитывать их традиционную, «понятийную» интерпретацию и в то же время сделает их пригодными для «формального» анализа разных языков. Но мы не преследуем такой цели на данном этапе. Пока мы допустим, что термины «существительное», «глагол», «прилагательное» и т. п. и другие грамматические термины не имеют никакой «понятийной» (или универсальной) значимости, но имеют в виду устанавливаемые на основе дистрибуционных критериев грамматические классы, которым можно дать любое произвольное обозначение. Теперь мы в состоянии предварительным образом рассмотреть разграничение между «грамматичностью» и «осмысленностью». (Мы не раз будем возвращаться к этому вопросу ниже.) Для простоты мы ограничимся здесь рассмотрением одного класса английских предложений (который мы опишем намеренно упрощенным образом). Рассматриваемый класс можно проиллюстрировать следую-щими, как мы полагаем, приемлемыми, примерами: (1) The dog bites the m an 'Собака кусает человека'. (2) The chimpanzee eats the banana 'Шимпанзе ест банан'. (2) The wind opens the door 'Ветер открывает дверь'. (4) The linguist recognizes the fact 'Лингвист признает факт'. (5) The meaning determines the structure 'Значение определяет структуру'. (6) The woman undresses the child 'Женщина раздевает ребенка'. (7) The wind frightens the child 'Ветер пугает ребенка'. (8) The child drinks the milk 'Ребенок пьет молоко'. (9) The dog sees the meat 'Собака видит мясо'. В традиционном грамматическом описании английского языка все эти предложения были бы определены как простые предложения субъектно-предикатной структуры. Кроме того, утверждалось бы, что (во всех примерах класса предложений, которым мы сейчас занимаемся) подлежащим является словосочетание (то есть единица, составленная из более чем одного слова), состоящее из Артикля (здесь the 'определенный артикль') и Существительного (например, dog), и что подлежащее (как это обычно бывает в английском языке) предшествует сказуемому; что сказуемым является словосочетание, состоящее из (переходного) Глагола (например, bites) и следующего за ним прямого дополнения, которое является словосочетанием, состоящим из Артикля и Существительного (например, man). О проиллюстрированном выше классе предложений может быть сделано много других утверждений: что подлежащее и глагол согласуются в «числе» (это означает, что если подлежащее-существительное стоит в единственном числе, глагол также будет встречаться в единственном числе, но если подлежащее-существительное стоит во множественном числе, то и глагол будет представлен во множественном числе; ср.: The dog bites vs. The dogs bite 'Собаки кусают'); что глагол «изменяется» по «временам» (то есть bites стоит в «настоящем времени», bit — это соответствующее «прошедшее время» данного глагола и т. д.). Все эти разнообразные утверждения можно более или менее удовлетворительно истолковать в рамках «формальной» грамматики (см. главным образом главы 7 и 8). Пока, однако, мы будем оперировать только тремя классами слов: артиклями, существительными и глаголами. Артикль можно рассматривать как одноэлементный класс, содержащий слово the; сокращенно обозначим его здесь как Т. Класс существительных и класс глаголов, сокращенно обозначаемые как N и V, содержат несколько тысяч слов, включая те, которые фигурируют в перечисленных выше «реальных» предложениях: N = {dog, man, chimpanzee, banana, wind, door, linguist, fact, meaning, structure, child, milk, meat, . . .} V = {bites, eats, opens, recognizes, determines, undresses, frightens, drinks, sees, ...} Задав эту пробную дистрибуционную классификацию английских слов (заметим, что мы тем самым ограничиваемся рассмотрением предложений, в которых встречаются существительные только в «единственном числе» и глаголы только в «настоящем времени»), мы можем предложить следующее грамматическое правило (которое приобретает исключительно линейную структуру; ср. § 6.1.1): ?1 : T + N + V + T + N. Знак ? ('сигма') обозначает «предложение»: мы используем греческую букву, а не латинское S (практика современных лингвистических работ не является единообразной в этом отношении), чтобы подчеркнуть различие в теоретическом статусе предложений и единиц, из которых строятся предложения, например слов (ср. гл. 5). Числовой индекс при ? означает, что это правило описывает только один класс предложений. Выбор числа совершенно произволен. Правило можно прочесть следующим образом: «Любое сочетание слов, которое получается в результате того, что на место символов Т, N и V в каждой позиции линейной формулы T + N + V + T + N подставляется любой элемент соответствующего класса, выбранный наугад из списка слов, содержащегося в лексиконе языка, представляет собой предложение типа 1». Грамматическое правило предполагает таким образом не только лексикон (или словарь), в котором всем словам языка придается соответствующая грамматическая классификация — N, V или Т, — но также одно или несколько правил лексической субституции для замены символов словесных классов словами. Существование таких правил мы здесь можем принять без доказательства: мы рассмотрим их в следующем разделе. Предложенное выше грамматическое правило вместе с соответствующими списками членов грамматических классов определяет все предложения в нашей «выборке» как грамматичные, со структурным описанием T + N + V + T + N. Мы сказали, что N и V могут содержать несколько тысяч членов. Чтобы упростить арифметические выкладки и получить, однако, некоторые разумные показания относительно количества английских предложений, порождаемых единственным правилом, которое было приведено выше, допустим, что каждый из двух классов N и V содержит ровно тысячу (103) элементов. При этом условии предложенное правило порождает ни больше, ни меньше как 1 ? 103 ? 103 ? 1 ? 103 = 109 (тысячу миллионов) предложений, имеющих одну и ту же структурную характеристику. Это только одно правило, и оно описывает очень простой класс очень коротких английских предложений. Речь идет, таким образом, об очень емком правиле — емком в том смысле, что оно несомненно порождает огромное число приемлемых предложений. Но оно, возможно, слишком емкое, поскольку оно также порождает (и определяет как грамматичные) очень многие предложения, которые не прошли бы испытание на приемлемость в нормальных условиях. (Ограничение «в нормальных условиях», какой бы неопределенный характер ни носило его практическое применение, не может быть опущено. Например, многие «обычно» неприемлемые «предложения» намеренно включаются в контекст лингвистических обсуждений или употребляются в сходных «ненормальных» условиях.) Поскольку все предложения, порождаемые вводимым нами правилом, тем самым определяются как грамматичные, мы должны либо внести в правило соответствующие коррективы, так, чтобы исключить некоторое количество предложений, которые мы рассматриваем как неприемлемые, либо дать объяснение их неприемлемости, если она поддается объяснению в общем описании языка, например в терминах несовместимости значений отдельных подклассов слов (или каким-нибудь иным способом). Как мы увидим, на самом деле эти два варианта не исключают друг друга. Но сначала рассмотрим, к чему ведет первая возможность в рамках «формальной» грамматики. 4.2.10. ВЫДЕЛЕНИЕ ПОДКЛАССОВ (СУБКЛАССИФИКАЦИЯ) Один очевидный путь внесения корректив в предложенный грамматический анализ — это разбить N и V на подклассы и формулировать не одно новое правило, а целое множество разных правил. Поэтому вновь разобьем слова на классы следующим образом: Na = {dog, man, chimpanzee, linguist, child, wind, ...} Nb = {banana, door, milk, meat, ...} Nc = {fact, meaning, structure, ...} \ Vd = {eats, bites, frightens, undresses, sees, ...} Ve = {recognizes, determines, sees, eats, ,..} Vf = {determines, ...}. Прежде чем продолжать, следует подчеркнуть ряд моментов в связи с данной переклассификацией. Во-первых, в принципе несущественно, каким образом мы пришли к данной классификации. Здесь не предполагается, что лингвистическая теория может или должна давать набор процедур для определения, или «установления», дистрибуционных классов, упоминаемых в грамматических правилах. Имеет значение вопрос о том, дает ли лингвисту именно одна, а не другая классификация возможность сформулировать серию правил таким образом, чтобы общее множество предложений, порождаемых грамматикой, включало максимальное число приемлемых предложений и минимальное число неприемлемых предложений. (Имеются дополнительные соображения, которые мы обсудим ниже в связи с разграничением «сильной» и «слабой» адекватности; см. § 6.5.7. Здесь их можно не принимать во внимание.) Второй заслуживающий упоминания момент заключается в том, что новые подклассы, несмотря на употребление индексов, оказываются теперь совершенно не связанными друг с другом. Иными словами, Na, Nb и Nc являются подклассами N только в том «несущественном» смысле, что мы от первоначальной пробной грамматической классификации перешли к последующей пробной классификации. В принципе же мы построили совершенно новую классификацию словаря и совершенно новую грамматику описываемого языка. Как мы увидим в следующем разделе, возможно пересмотреть понятие дистрибуционной классификации, которым мы сейчас оперируем, таким образом, чтобы Na, Nb и Nc можно было рассматривать как подклассы более широкого класса N, a Vd, Ve, Vf — как подклассы V. Наконец, следует отметить, что мы ввели определенное количество случаев многократного вхождения: слово determines встречается как в классе Ve, так и в классе Vf , а слово sees — как в классе Vd, так и в классе Ve. Независимо от того, какие возражения может вызвать двойная классификация этих слов, она имеет еще то нежелательное следствие, что в рамках предполагаемой ею модели sees в предложении типа The child sees the banana 'Ребенок видит банан' представляет собой, с грамматической точки зрения, совершенно другой элемент, нежели sees в таких предложениях, как The child sees the meaning 'Ребенок понимает [букв, видит] смысл'. Мы еще вернемся к этому вопросу в следующем разделе. Новая классификация рассматриваемых слов предполагает замену прежнего правила целым множеством правил (следует заметить, что каждое из них определяет совершенно особый тип предложения): a) ?1 : T + Na + Vd + T + Na (ср. The dog bites the man) b) ?2 : T + Na + Vd + T + Nb (cp. The chimpanzee eats the banana) c) ?3 : T+ Na + Ve + T + Nc (cp. The linguist recognizes the fact) d) ?4 : T + Nc + Vf + T + Nc (cp. The meaning determines the structure). Хотя этих четырех правил достаточно, чтобы породить девять предложений из нашей «выборки» (и очень многие другие), очевидно, что теперь потребуются еще какие-то правила, описывающие другие предложения, состоящие из употребляемых в «выборке» слов, которые мы были бы склонны рассматривать как приемлемые (The banana frightens the linguist [букв. 'Банан пугает лингвиста'] и т. п.). Мы приглашаем читателя построить некоторые дополнительные правила, а также продолжить приведенные выше списки слов. Самым важным моментом, возникающим в связи с пересмотром грамматических правил, является то, что заново определяются границы между грамматичными и неграмматичными предложениями английского языка. Такие сочетания слов, как *The banana bites the meaning, *The structure drinks the chimpanzee и т. п., которые, согласно нашему предположению, являются неприемлемыми как английские высказывания, теперь определяются как неграмматичные. С другой стороны, существует много других неприемлемых высказываний, которые допускаются правилами как грамматичные: *The chimpanzee drinks the door, *The dog undresses the wind и т. Д. В принципе мы могли бы надеяться постепенно сделать классификацию слов и систему правил все более и более подробными, внося все новые и новые исправления, до тех пор пока наша грамматика не будет способна порождать максимальное число приемлемых предложений и минимальное число неприемлемых предложений. С каждой последующей модификацией — и в этом теоретическое значение данного примера — границы грамматичное очерчиваются для описываемого языка заново. С «формальной» (vs. «понятийной») точки зрения, грамматичность — это не более чем приемлемость в той мере, в какой она может быть описана с помощью определенного множества правил и определенной классификации лексических и грамматических элементов языка. (Пока разграничение между «лексическими» и «грамматическими» элементами, вкравшееся в данную формулировку, можно игнорировать: «лексические и грамматические элементы» можно понимать как «слова».) 4.2.11. НЕДЕТЕРМИНИРОВАННОСТЬ ГРАММАТИКИ Описывая конкретный язык, лингвист должен так или иначе установить пределы грамматичности. На его решение провести соответствующие границы (если решение принимается сознательно, путем выбора из представляющихся альтернатив) обычно оказывают влияние два следующие основные фактора. Первый может быть назван законом «снижения рентабельности». Классификация слов по их дистрибутивным свойствам может, вообще говоря, быть гораздо более детальной, чем это представлялось возможным или даже желательным традиционным грамматикам. Однако рано или поздно в своем стремлении исключить положительно неприемлемые предложения при помощи все более дробной классификации составляющих их слов исследователь столкнется с такой ситуацией, когда он вынужден будет устанавливать все новые и новые правила, каждое из которых будет иметь отношение к очень небольшому количеству предложений; при этом придется устанавливать такое большое количество пересекающихся классов слов, что может быть утрачено какое бы то ни было подобие общности. Именно это мы имеем в виду, говоря о законе «снижения рентабельности»: в определенный момент (вопрос о том, когда именно наступает этот момент, заслуживает специального рассмотрения и обсуждения) сложность правил становится слишком «дорогостоящей» относительно их «производительности»; каждое начинает охватывать сравнительно небольшое число приемлемых и неприемлемых предложений. Второй фактор является, впрочем, не менее важным. В связи с тем, что предложения описываемого языка столь многочисленны (как мы увидим в дальнейшем, может оказаться желательным — как с теоретической, так и с практической точки зрения — считать их число бесконечным), нельзя надеяться с определенностью решить для каждого порожденного грамматикой предложения, является ли оно приемлемым или неприемлемым. На самом деле, описывая какой-либо язык, сразу же приходится сталкиваться с разногласиями среди носителей этого языка относительно приемлемости предложений, порождаемых правилами, которые были ориентировочно установлены исследователем. Таким образом, существует реальная и, возможно, неустранимая проблема недетерминированности в отношении приемлемости и неприемлемости. Это, по-видимому, должно привести к заключению, что грамматическая структура языка в конечном счете не детерминирована. Дело не только в том, что лингвисты по-разному понимают, что составляет оптимальную степень общности правил, и по-разному оценивают приемлемость тех или иных классов предложений. Дополнительная трудность заключается в том, что порождение одной серии предложений определенного типа может чрезвычайно затруднить порождение другой серии предложений иного типа в рамках теории, установленной для первой серии предложений. Некоторые из возникающих при этом проблем будут упомянуты ниже (см. § 8.3.6 и сл.). Наблюдающийся в настоящее время прогресс в развитии грамматической теории, возможно, уменьшит число подобных проблем или даже вовсе устранит их; но пока это еще довольно трудные проблемы. Таким образом, мы можем вновь сформулировать как общий принцип грамматической теории (на который не повлияет ничто, сказанное в последующих главах о природе и способе действия грамматических правил) следующий факт: ответить на вопрос, является ли то или иное сочетание слов грамматичным или неграмматичным, можно только обратившись к конкретной системе правил, которая или порождает его (и таким образом определяет как грамматичное), или же не порождает (и тем самым определяет как неграмматичное). Большинство теоретиков грамматики, включая и тех, кто внес наибольший вклад в развитие трансформационной грамматики (в частности, Хомский), по-видимому, отвергает этот принцип. Они предполагают, что грамматическая структура языка детерминирована, и носители языка знают ее «интуитивно» (или «неявно»). Это представляется чрезмерно сильным допущением. Несомненно, носители языка согласятся, что определенные наборы высказываний «сходны» или «однородны» или «различны» в том или ином отношении. Эти интуитивные представления в той мере, в какой они могут быть установлены, составляют важную часть данных лингвиста; и он может описывать их, выделяя разные виды приемлемости (или правильности) и разные виды связи между предложениями. Но он не обязан предполагать, что существует какое-либо прямое соответствие между «интуитивными» представлениями говорящих и утверждениями, сделанными лингвистом. Не следует преувеличивать разницу в мнениях среди лингвистов по этому вопросу. Утверждать, что грамматическая структура языка в конечном счете не детерминирована — не то же самое, что утверждать, что никакая часть грамматической структуры не является детерминированной. Можно представить себе много сочетаний слов (например: *They likes she, *The dog bite the man и т. д.), которые все лингвисты сразу охарактеризуют не только как неприемлемые, но также и как «неграмматичные» (не обязательно формулируя при этом ряд грамматических правил). Можно считать, что их непосредственная реакция основана на «интуитивном» знании грамматической структуры литературного английского языка; с равным успехом можно говорить, что законы построения высказываний, нарушаемые рассматриваемыми сочетаниями, носят столь общий характер, что они получат отражение в любой грамматике литературного английского языка. Однако предложения, подчиняющиеся менее общим законам, могут в разных описаниях характеризоваться как грамматичные или неграмматичные неодинаковым образом. И во всяком случае здесь «интуитивные» представления лингвистов и носителей языка ненадежны и противоречивы. 4.2.12. «ГРАММАТИЧНОСТЬ» И «ОСМЫСЛЕННОСТЬ» Как мы видели ранее в настоящем разделе, кажется целесообразным говорить о различных видах приемлемости. Традиционное разграничение между «грамматичностью» и «осмысленностью» (не говоря уже о других видах приемлемости, упомянутых ранее) не затрагивается выводом, к которому мы только что пришли: что пределы грамматики в конечном счете не детерминированы; или, скорее, что каждая грамматика сама определяет свои границы и в этом смысле делает их детерминированными. Когда мы говорим, что определенное высказывание неграмматично (по отношению к конкретной грамматике), мы не подразумеваем при этом, что оно также неприемлемо по иным причинам. О некоторых неприемлемых сочетаниях слов мы будем говорить, что они грамматичны, но бессмысленны; о других — что, хотя они и грамматичны, и осмысленны, они обычно не встречаются, так как ситуация, «выражаемая» ими, вряд ли может возникнуть. Еще об одном классе сочетаний слов мы были бы склонны сказать, что они и неграмматичиы, и бессмысленны. На одном конце «континуума» приемлемости должны находиться определенные сочетания слов, приемлемость или неприемлемость которых объясняется только с помощью грамматики (ср. Не gives 'Он дает', They give 'Они дают' vs. *Не give, *They gives). На другом конце этого континуума грамматическое описание бесполезно. Но найдется много высказываний, при описании которых имеют смысл как грамматическое объяснение, так и объяснение, апеллирующее к значению составляющих их слов; и именно этот факт делает в значительной степени обоснованными «понятийные» определения некоторых грамматических классов в тех или иных языках («глаголы движения», «существительное мужского рода», «локативное словосочетание» и т. п.). Мы вернемся к вопросу о коррелятивности между грамматической и семантической классификацией слов в следующем разделе. 4.2.13. ТЕРМИН «ГЕНЕРАТИВНЫЙ» («ПОРОЖДАЮЩИЙ») Но прежде мы должны сказать еще несколько слов о терминах «порождать» (или «генерировать») и «генеративный», поскольку их часто понимают неправильно. Прежде всего следует подчеркнуть негативный момент: генеративная грамматика — не обязательно трансформационная грамматика (см. §6.6.1). Термины «генеративный» и «трансформационный» часто смешивают, потому что их в одно и то же время ввел в лингвистический обиход Хомский. (Примерно в том же значении, что и Хомский, термин «трансформационный» употреблял также и Хэррис.) Хомский и его последователи обычно вкладывают в термин «генеративный» одновременно два различных смысла: (i) «проективный» (или «предиктивный») и (ii) «эксплицитный» («формальный» vs. «неформальный»). В этом разделе он использовался как в одном, так и в другом понимании. Первоначально он был введен в значении «проективный» (или «предиктивный»): он должен был относиться к любому множеству грамматических правил, которые эксплицитно или имплицитно описывали данный корпус предложений, «проецируя» их на большее множество предложений или рассматривая их как «выборку» из этого множества. Грамматика такого типа является «предиктивной» в том смысле, что она устанавливает грамматическую правильность не только «реальных», но и «потенциальных» предложений. Важно понять, что большинство грамматик, когда-либо написанных за всю историю лингвистики, являются генеративными в первом значении этого термина. Не стоило бы специально указывать на это, если бы не тот факт, что различие между предиктивностью и прескриптивностью, то есть предписыванием норм «правильного употребления», не всегда принимается во внимание (ср. § 1.4.3). Но впоследствии в этом разделе мы пользовались термином «генеративный» в несколько особом значении «эксплицитного» (ср. «порождать», «характеризовать» в § 4.2.8). Оно близко к одному из значений, в котором термин «порождать» используется в математике, и, действительно, заимствован из нее. Рассмотрим, оставляя в стороне технические детали, следующее утверждение: «Число 2 порождает множество или ряд чисел 2, 4, 8, 16, 32, ...» Это бесконечное множество чисел может быть упорядочено, как это сделано выше, в последовательность «возрастающих степеней 2», где число 2 — основание данного ряда. Каждому числу, порождаемому этим основанием, удовлетворяет некоторое значение функции 2n (где 2 — основание, а n — переменная, принимающая натуральные значения 1, 2, 3, 4, ...). Каждое число, как бы велико оно ни было, либо принадлежит множеству, порождаемому в определенном выше смысле числом 2, либо не принадлежит; вопрос о том, принадлежит ли оно этому множеству («степеней 2»), в принципе разрешим. Разрешающая процедура для любого данного числа может иметь следующий вид: порождается рассматриваемый ряд вплоть до числа, равного или большего по величине данного числа; затем данное число проверяется на идентичность с каждым из чисел, порождаемых основанием. Таким образом мы могли бы определить, например, что 9 не принадлежит этому множеству, поскольку оно не равно ни 2, ни 4, ни 8, ни 16 (первое число ряда, большее 9). Кроме того, чтобы подчеркнуть аналогию с грамматикой, можно сказать, что каждому числу этого множества при порождении ставится в соответствие его «структурное описание»: «структурное описание 64, например, — это 2n, где n = 6». Когда мы говорим, что грамматика порождает предложения языка, мы подразумеваем, что она составляет систему правил (к которым прилагается словарь), сформулированных таким образом, что они дают в принципе разрешающую процедуру для любого сочетания элементов языка (назовем их в этом случае «словами») в смысле, более или менее близком вышеупомянутому. Кроме того, грамматика не только «решает», является ли некоторое данное сочетание грамматически правильным или нет (порождая или не порождая сочетание символов, которое может быть проверено на «идентичность» с рассматриваемым высказыванием), но она снабжает каждое грамматически правильное сочетание по крайней мере одним структурным описанием. (Ниже мы увидим, что предложения более чем с одним структурным описанием определяются как грамматически неоднозначные; см. § 6.1.3.) Это второе, более или менее близкое к математическому, значение термина «порождать» предполагает применительно к грамматике строгую и точную характеристику природы грамматических правил и способа их действия: оно предполагает формализацию грамматической теории. На протяжении этого раздела наша интерпретация термина «формальная грамматика» перешла, таким образом, от противопоставления «формальный» vs. «понятийный» к противопоставлению «формальный» vs. «неформальный». Этот переход отражает историческое развитие грамматической теории за последние десять или пятнадцать лет. 4.2.14. «ДИСТРИБУЦИЯ» И «ПРОЦЕДУРЫ ОТКРЫТИЯ» * Принципы дистрибуционного анализа (определяющего противопоставление «формальная» vs. «понятийная» грамматика) наиболее тщательно и широко были рассмотрены Хэррисом, особенно в книге «Методы структурной лингвистики» (опубликованной в 1951 г., но написанной несколькими годами раньше). Хэррис и другие американские лингвисты того времени разработали эти принципы в рамках «процедурной» лингвистики, то есть определенного набора исходных представлений относительно природы лингвистической теории и методики, которые не всеми были приняты в то время и пользуются еще меньшей популярностью сейчас. В частности, предполагалось, что основная задача структурной лингвистики состоит в определении методики или процедуры, которая может применяться к корпусу засвидетельствованных высказываний и, при минимальном использовании суждений информанта относительно «тождеств» и «различий», может гарантировать получение из самого корпуса правил грамматики. По этой причине термины «дистрибуция» и «структуралистский» стали в силу чисто исторических причин связываться с той точкой зрения, согласно которой можно сформулировать «процедуры открытия» для установления правил конкретных грамматик на основе засвидетельствованных высказываний. Должно быть ясно, что термин «дистрибуция» используется в этой книге без подобных побочных импликаций. Следует также понять, что труды Хэрриса и его коллег с их сильной тенденцией к точной формулировке дистрибуционных принципов послужили основанием, на котором была построена генеративная грамматика со времени публикации работы Хомского «Синтаксические структуры» в 1957 г. 4.3. ГРАММАТИКА И СЛОВАРЬ 4.3.1. АНАЛИЗ И СИНТЕЗ Как мы уже видели в предыдущем разделе, каждая грамматика предполагает некоторый словарь (или лексикон), в котором слова языка классифицируются в соответствии с их вхождением в дистрибуционные классы, упоминаемые в грамматических правилах. Как грамматику, так и словарь можно рассматривать с двух различных точек зрения, в зависимости от того, занимается ли лингвист анализом («распознаванием») корпуса высказываний или синтезом («образованием») грамматически правильных предложений. Хотя из соображений практического удобства считается, что словарь и грамматика организованы до некоторой степени различным образом в соответствии с тем, используются ли они для «распознавания» или «образования», важно понять, что сами по себе они нейтральны по отношению к этому разграничению. Любой корпус засвидетельствованных предложений может быть удовлетворительно описан лишь как «выборка» из предложений, порождаемых грамматикой (см. § 4.2.8). Таким образом, генеративная и «описательная» грамматика не противопоставляются друг другу. Однако тот факт, что грамматика нейтральна в принципе по отношению к анализу и синтезу, не означает, что принятие одной, а не другой точки зрения не имеет никаких практических последствий. Если грамматика предназначается для синтеза, удобно организовать словарь так, чтобы можно было легко найти все элементы некоторого класса слов для замены любым из них соответствующего символа класса (например, N), что предполагается правилами лексической субституции (см. § 4.3.2). Очевидный способ сделать это — организовать лексикон как множество списков, обладающих следующей формой: N = {man, boy, chimpanzee, . . .}. С другой стороны, если мы занимаемся анализом данного текста, будет легче работать с эталонным списком, в котором слова упорядочены в соответствии с некоторым принципом (например, по алфавиту), что позволит нам быстро найти любые отдельные слова, встречающиеся в анализируемом предложении, и распознать их грамматические свойства, например: beauty 'красота': Существительное die 'игральная кость; умирать': Существительное, Глагол warm 'теплый; греть': Прилагательное, Глагол. Наши обычные словари принадлежат к этому второму типу. Традиционные грамматики обычно не составляли списков первого типа, за исключением списков для «неправильных» форм (которые. они могли записывать в грамматике, так же как и перечислять в алфавитном порядке в словаре). Они допускали возможность построения списков слов для целей «синтеза» на основе значения отдельных слов и определений «частей речи». Некоторые современные генеративные грамматики, или грамматические очерки, предусматривают частичные списки для каждого класса слов в отдельности (мы рассмотрим природу этих списков ниже). Различие между двумя видами словаря не принципиально, а касается, скорее, удобства. Современные генеративные грамматики упомянутого типа более заинтересованы в установлении грамматических классов, требуемых для описания рассматриваемого ими языка, нежели в исчерпывающей классификации всех слов в этом языке. Если все слова языка не классифицированы соответствующим образом в словаре, грамматика не будет генеративной в смысле «эксплицитности» (см. § 4.2.13). Одно из следствий принятия точки зрения анализа, а не синтеза заключается в следующем. Если лингвист знает, что его описание отдельного языка будет использовано только для анализа зафиксированного материала (например, в некоторых проектах автоматического анализа письменных текстов для создания машинного перевода или библиотечного каталога и поиска информации), он может позволить себе менее исчерпывающую классификацию словаря и менее полное грамматическое описание языка. Например, есть много английских существительных, оканчивающихся на ness (например, goodness 'доброта', correctness 'правильность' и т. д.). Большинство из них, как и два приведенных здесь примера, могут быть «образованы» от прилагательных (например, good 'хороший', correct 'правильный' и т. д.). Не вдаваясь здесь в природу «словообразования» (см. § 5.4.2), мы можем считать одно слово, существительное, образованным от другого, прилагательного, с помощью следующей формулы: Ax + ness = Ny. (Это можно прочесть следующим образом: «Любое слово, состоящее из члена класса слов Аx и ness, является членом класса слов Ny».) Поскольку это весьма продуктивное словообразовательное правило английского языка, можно решить, что его следует включить в грамматику; и все слова, оканчивающиеся на ness, которые можно образовать с помощью этой формулы, могут быть изъяты из словаря. Если же мы занимаемся синтезом, мы должны решить, какие прилагательные принадлежат классу Аx; например, включает ли этот класс слова true 'верный' и strong 'сильный' с тем, чтобы trueness и strongness (в дополнение к truth 'правда' и strength 'сила' или вместо них) порождались как грамматичные или исключались как неграмматичные. Но грамматика «распознавания» не нуждается в решении этого вопроса. Эта грамматика могла бы вполне довольствоваться более общим правилом A + ness = Ny («Любое слово, встречающееся в предложении в позиции, в которой допустимо Ny, и которое можно разложить на А и ness, должно быть принято программой распознавания»). Если бы trueness и strongness встретились в анализируемом тексте, они были бы проанализированы и признаны грамматичными; если нет, то данный вопрос не релевантен. (Слова truth и strength были бы перечислены в словаре или анализировались бы на основе иных правил. Использованный здесь пример взят из действительной программы вычислительной машины, которая успешно анализировала очень многие английские деривационные образования.) С различием точек зрения не связано никакое принципиальное различие. Формула A + ness = Ny порождает одно и то же множество слов, используется ли она для анализа или синтеза (предполагается, что она относится к одному и тому же списку прилагательных). Но, занимаясь исключительно анализом, можно позволить себе некоторые вольности. Можно намеренно порождать (в абстрактном, математическом значении — и именно в этом значении следует всегда понимать этот термин) множество предложений, которое включало бы ряд подлежащих исключению предложений, исходя из предположения, что они так или иначе не встретятся. Исключение предложений, которые предположительно не встретятся, значительно увеличило бы «затраты» (см. § 4.2.11). Этот принцип «эффективности затрат» часто применяется при автоматическом анализе языка с помощью компьютера, поскольку принцип «снижения рентабельности» имеет весьма прямую экономическую интерпретацию (в виде дополнительного времени, необходимого для программирования, излишних затрат времени компьютера и т. д.). Следует, впрочем, учесть возможность неправильного понимания соотношения анализа и синтеза. Тот факт, что грамматика нейтральна по отношению к анализу и синтезу, не означает, что анализ — это просто нечто обратное синтезу (или vice versa). Не следует, например, полагать, что программа вычислительной машины могла бы проходить «сверху вниз» по набору правил (и от грамматики к словарю) при «образовании» предложений и «снизу вверх по тому же набору правил (и от словаря к грамматике) при «рас познавании» конкретного корпуса материала. Как «образование», так и «распознавание», производится ли оно говорящими и слушающими или компьютером, предназначенным для моделирования их речевого «поведения», по-видимому, предусматривают «обратную связь» между этими двумя процессами (см. § 3.2.9). В исследовании этой проблемы с психологической точки зрения достигнуты пока лишь незначительные успехи; некоторые «психолингвистические» исследования были неудачными из-за непонимания того факта, что «генеративный» («порождающий») не означает «производящий». Отсюда этот предостерегающий абзац. 4.3.2. ПРАВИЛА ЛЕКСИЧЕСКОЙ СУБСТИТУЦИИ Теперь мы можем вернуться к обсуждению структуры словаря. Для простоты будем по-прежнему опираться на наше весьма простое представление о грамматических правилах. Хотя оно будет пересмотрено в последующих главах, этот пересмотр не окажет влияния на сделанные здесь общие утверждения. Итак, вернемся к первому правилу, использованному в предыдущем разделе: ?1 : T + N + V + T + N, и к предполагаемым им классам слов: T = {the} N = {man, dog, chimpanzee, . . .} V = {bites, eats, opens, . . .}. Процесс лексической субституции (подстановка конкретных слов на позиции, установленные соответствующим грамматическим правилом; см. § 4.2.9) можно описать следующим образом: каждый случай появления символа грамматического класса в структурном описании предложения заменяется на любой член означенного класса, причем этот член берется из списка данного класса, приведенного в словаре. (Когда все символы грамматических классов заменены, или «переписаны», посредством многократного применения принципа лексической субституции, на «выходе» генеративной системы получается предложение, снабженное соответствующим структурным описанием.) Операция лексической субституции может быть формализована посредством следующего правила: Х > х|х ? Х. «Замени X, где X — переменная, принимающая значение всех грамматических классов, упоминаемых в генеративной системе (например, Т, N или V), на х, где х — любой член класса X». Последовательное применение этого правила лексической субституции превратит T + N + V + T + N в некоторое предложение типа The dog bites the man, как это представлено деревом на рис. 5. (Заметим, что различие между той частью «выхода», которая выводится из грамматического правила, и частью, полученной из словаря, представлено на дереве различием между сплошной и прерывистой линией. В настоящей работе мы будем везде придерживаться этого удобного соглашения.) 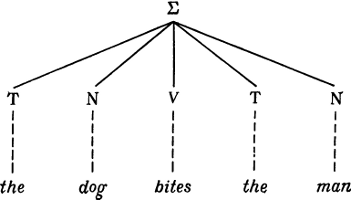 Рис. 5. Поскольку правила лексической субституции действуют одинаковым образом, независимо от «значения», принимаемого Х-ом, мы можем рассматривать списки слов как множество правил, прилагаемых к грамматике, и таким образом обойтись без обобщенного правила лексической субституции. Принимая эту точку зрения (которую мы вскоре пересмотрим), мы следуем практике Хомского и других авторов первых работ по генеративной грамматике. Мы можем, следовательно, организовать словарь так, чтобы он принял следующую форму: T > {the} N > {man, dog, chimpanzee, . . .} V > {bites, eats, opens, . . .}. Стрелки можно интерпретировать как инструкцию заменить (или «переписать») элемент, находящийся слева от стрелки, на один из элементов, перечисленных справа от стрелки, например: 'y > z' означало бы «замени у на z (при условиях, определяющих систему правил)». Любая система правил, каждое из которых представлено в такой форме (способ их действия будет более подробно рассмотрен в гл. 6), называется системой подстановки (или системой правил подстановки). Теперь используем стрелку подстановки также и для грамматического правила и объединим грамматическое правило и правила лексической субституции в одну систему: (1) ?1 > T + N + V + T + N (2) T > {the} (3) N > {man, dog, chimpanzee, . . .} (4) V > {bites, eats, opens, . . .}. Это весьма простая генеративная грамматика, которую мы расширим, с тем чтобы она учитывала некоторые результаты деления классов слов на определенные подклассы. В предыдущем разделе мы отмечали, что в рамках допущений, принятых нами при рассмотрении формальной грамматики, любая переклассификация слов в словаре производит не подклассы исходных более широких классов, а совершенно не связанные друг с другом новые классы. С грамматической точки зрения этот недостаток может быть исправлен посредством введения добавочных правил, а именно: N > {Na, Nb, Nc} V > {Vd, Ve, Vf}. Теперь мы должны внести поправки в правила лексической субституции (увеличив их число). Таким образом, новая система, включающая грамматику и словарь, примет следующий вид: (1) ?1 > T + N + V + T + N (2) N > {Na, Nb, Nc} (3) V > {Vd, Ve, Vf} (4) Na > {man, dog, chimpanzee, . . .} (5) Nb > {banana, door, milk, . . .} (6) Nc > {fact, meaning, structure, . . .} (7) Vd > {eats, bites, frightens, . . .} (8) Vd > {recognizes, . . .} (9) Vf > {determines, . . .}. Эта система правил формализует в пределах грамматики тот факт, что Na, Nb и Nc представляют собой подклассы N (члены этих подклассов — «существительные»), а Vd, Ve,и Vf - подклассы V (члены — «глаголы»). Следовательно, в целях формализации этого факта наша система вводит дополнительный «слой» грамматической структуры (ср. рис. 6, представляющий дополнительный «слой» посредством ветвей «дерева», связывающих N и Na и V и Vd). Однако это происходит за счет того, что система допускает в качестве грамматически правильных те самые сочетания подклассов, для запрещения которых и предназначался процесс субклассификации. (В вышеприведенном наборе правил нет никаких ограничений, препятствующих тому, чтобы избрать, скажем, Nb для заполнения второй позиции при Vd в третьей позиции и Nc в пятой позиции.) 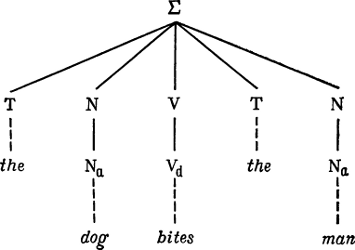 Рис. 6. Речь идет здесь о принципе синтагматической обусловленности, или совместимости, между одним и другим подклассом слов, то есть о том, что обычно называют лексической селекцией. На данном этапе мы занимаемся структурой словаря и не будем вдаваться в грамматические аспекты этой проблемы. Допустим просто, что в принципе возможна такая формализация (использующая контекстно-связанные правила; см. § 6.5.1), которая позволила бы нам сохранить понятие субклассификации, выраженное в правилах (2) и (3), и тем не менее порождать желаемые сочетания подклассов. 4.3.3. ГРАММАТИЧЕСКИЕ ПРИЗНАКИ * Теперь мы можем представить себе все более и более дробную классификацию словаря языка (вплоть до «снижения рентабельности»). Грамматику можно расширить, например, таким образом, чтобы она включала такие добавочные правила, как Na > {Na1, Na2} Nb > {Nb1, Nb2} Na1 > {Na11, Na12} и т. д. Каждое последующее выделение подклассов такого рода предполагает увеличение числа правил лексической субституции. Более того, очевидно, что эта формализация основывается на весьма частном (и, как мы увидим, ошибочном) предположении относительно грамматической структуры языка. Эти правила делят весь словарь на иерархически упорядоченные классы и подклассы (см. рис. 7) так, что Na11 и Na12 полностью принадлежат Na1; Na1 полностью принадлежит Na, а Na полностью принадлежит N и т. д. Это предположение лежало в основе первых генеративных грамматик, принявших подстановочную систему формализации (введенную в лингвистику Хомским). 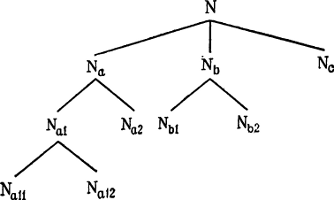 Рис. 7. Оно неудовлетворительно по двум причинам. Во-первых, оно ведет к увеличению числа отдельных списков в словаре при соответственно высокой степени многократного вхождения (см. § 4.2.10). Во-вторых, и это более важно, оно делает формулировку грамматических правил более сложной, чем этого требуют «факты». Цитируя Хомского: «Трудность состоит в том, что такая субкатегоризация [то есть выделение подклассов в словаре] обычно не является строго иерархической, а включает в себя перекрестную классификацию. Так, например, существительные в английском языке делятся на Имена Собственные (John, Egypt) и Имена Нарицательные (boy 'мальчик', book 'книга') и бывают Человеческими (John, boy) и Нечеловеческими (Egypt, book)... Но если субкатегоризация задана правилами подстановки, то какое-то из этих различий должно доминировать, и тогда другое нельзя будет сформулировать естественным образом». Например, если класс существительных сначала делится на Собственные Имена существительные и Нарицательные Имена существительные, затем каждое из них в свою очередь подразделяется на подклассы «Человеческий» и «Нечеловеческий», единственный способ сформулировать правило, относящееся ко всем «Человеческим существительным», — это отнести его к обоим совершенно не связанным классам «Собственные Человеческие» и «Нарицательные Человеческие» (поскольку в словаре нет списка «Человеческих Имен существительных»). Как пишет далее Хомский, «по мере углубления разложения [т. е. с каждой последующей субклассификацией] проблемы такого рода становятся столь значительными, что указывают на серьезную неадекватность грамматики, которая состоит только из правил подстановки». Мы не будем рассматривать предлагаемое Хомским исправление грамматических правил для решения этих проблем: в настоящей главе мы имеем дело с очень простой системой. Что касается словаря, то результат «перекрестной классификации» ясен. Предполагается, что каждое слово должно быть «индексировано» таким образом, чтобы можно было подобрать, например, любое «человеческое» существительное (независимо от того, «собственное» оно или «нарицательное»), любое «конкретное» существительное (независимо от того, «одушевленное» оно или «неодушевленное») и т. д. С этим типом классификации, или «индексирования», обычно связывают специальный термин признак (ср. в известной мере аналогичное использование термина «признак» в фонологии). Мы предполагаем, что каждое слово должно быть приведено в словаре (который уже не может теперь иметь вид системы правил подстановки, включенной в грамматику) вместе с набором признаков, например: boy : [нарицательное], [человеческое], [мужской род], ... door : [нарицательное], [неодушевленное], ... Правило или правила лексической субституции придется, следовательно, формулировать так, чтобы можно было подобрать отдельное слово согласно одному или более указанным признакам. На каком этапе в системе порождения будут применяться правила лексической субституции — это спорный вопрос. Следует отметить, однако, что, хотя мы отказались от словаря, представленного в виде набора правил вида Na > {boy,...}, наше более общее правило остается в силе (см. § 4.3.2): Х > х|х ? Х. («замени X на х, где х — член класса слов X»). Различие в том, что теперь X — это класс слов, удовлетворяющих специальной признаковой характеристике. Так, если порождаемое грамматикой предложение предусматривает «нарицательное, человеческое» существительное «мужского рода», то X —это класс, состоящий из всех слов лексикона, содержащих в качестве грамматических признаков [на-рицательность], [человечность], [мужской род], например boy. Однако списка членов этого сложного класса не существует. 4.3.4. ИМПЛИКАЦИИ КОНГРУЭНТНОСТИ ГРАММАТИЧЕСКОЙ И СЕМАНТИЧЕСКОЙ КЛАССИФИКАЦИИ Теперь мы можем перейти к следующему вопросу. Хотя этот вопрос почти не имеет отношения к пониманию генеративной грамматики, как она излагалась до сих пор в опубликованных работах, он начинает приобретать определенное значение в связи с некоторыми недавними предложениями, касающимися формализации семантики. Как мы увидим в последующих главах, есть серьезные основания полагать, что слияние грамматики и семантики приведет к некоторому сближению между «формальной» и «понятийной» грамматикой. По этой причине особенно важно не упустить из виду некоторые общие положения. Термины, которые мы использовали для обозначения признаков, упоминавшихся в предыдущем абзаце («собственное», «нарицательное», «одушевленное», «мужской род» и т. п.), трактовались как грамматические. Мы не отказались от того принципиального положения, согласно которому подобные термины, обозначая классы, упоминаемые в грамматических правилах, представляют собой условные наименования классов, основанных, как мы согласились считать, на дистрибуции. Однако эти условные наименования (по происхождению связанные с «понятийной» грамматикой) явно несут определенные семантические импликации. Мы уже упоминали о конгруэнтности, или взаимном соответствии, которое наблюдается в разной степени между грамматической и семантической структурой языка; и мы вернемся к этому вопросу позже. Так, можно полагать, что большинство грамматически «одушевленных» существительных будет обозначать людей или животных, что большинство существительных «мужского рода» будет обозначать мужчин и т. д. Нередко, однако, между классификацией слов, использующей такие признаки, как «одушевленность» или «мужской род», и классификацией, основанной на значении слов, могут наблюдаться противоречия (ср. гл. 7). Это давно признано и является главной причиной, в связи с которой большинство лингвистов отказалось от «понятийной» грамматики. В то же время следует ясно понимать, что при достаточно полном описании языка в словарь должны включаться как грамматические, так и семантические сведения о каждом приведенном в нем слове. Семантическую информацию, возможно, следует организовать таким образом, чтобы во всех тех случаях, когда между грамматической и семантической классификацией наблюдается соответствие, было бы возможным вывести часть грамматической информации (требуемой для действия грамматических правил) из описания значения слова. Предположим, например, что слово man приводится в словаре вместе с описанием его значения (в какой бы то ни было форме), и, кроме того, предположим, что из этих сведений можно вывести посредством соответствующего правила, что денотатом man (по крайней мере в одном из значений) является взрослый человек мужского пола (NB: из этого не следует, что значение man — это 'взрослый, человек, мужского пола': эта оговорка существенна в свете того, что будет сказано в главах по семантике). При таком условии мы можем вывести из этого грамматическую характеристику слова man, включающую признаки [мужской род], [человечность], что имплицирует [одушевленность] и т. д. Это — грамматическая классификация, так как она предназначена для объяснения таких дистрибуционных фактов, как употребление форм who 'кто' vs. which 'который, что'; he, him, his 'он, ему, его...' vs. she, her 'она, ее' vs. it, its 'оно, его' и т. д. Например, *The man which came... или *The man washed her own shirt должны быть отвергнуты как неприемлемые и, как мы полагаем, неграмматичные. Может показаться на первый взгляд, что предложение выводить грамматическую классификацию слова из описания его значения противоречит принципам формальной грамматики, изложенным в предыдущем разделе. Это не так, если мы будем соблюдать следующее важное условие: из сферы действия любого общего правила, установленного для выведения грамматических признаков из содержащегося в лексиконе описания значения слова, должны быть явным образом (путем специальной пометы) исключены слова с противоречащим признаком. Предположим, например, что все слова, обозначающие людей, обладают грамматическим признаком [человечность], имплицирующим также признак [одушевленность], и, кроме того, что они принадлежат к [мужскому роду], если обозначают лиц мужского пола, и к [женскому роду], если обозначают лиц женского пола. Это общий закон, применяемый в том случае, если данному слову не приписана в словаре противоречащая грамматическая характеристика. Теперь мы констатируем (и допустим, что мы располагаем соответствующим грамматическим аппаратом для формализации этого утверждения), что [неодушевленность] противоречит [одушевленности]. Поскольку слову man в словаре не приписаны никакие противоречащие грамматические признаки, переход семантической информации в грамматическую будет подчиняться действию общих правил. Но слово child 'дитя' могло бы войти в словарь с признаком [неодушевленность], с тем чтобы допустить такие предложения, как The child ate its dinner 'Ребенок съел свой обед'. Впрочем, сразу же понятно, что факты значительно более сложны, чем предполагает эта простая методика. Такие предложения, как The child ate his dinner и The child ate her dinner, также приемлемы. Мы могли бы, следовательно, ввести разграничение между признаками [неодушевленность] и [средний род]. Обычно [неодушевленность] (независимо от того, включен ли этот признак в грамматическую информацию или выведен для отдельного слова из анализа его значения) имплицирует [средний род]; а [одушевленность] имплицирует либо [мужской род], либо [женский род], причем, если слово не определено как одно или другое, выбор рода произволен. Но можно было бы рассмотреть возможность приписать слову child как признак [одушевленность], так и признак [средний род]. В этом случае мы должны сформулировать грамматические правила таким образом, чтобы наличие признака [средний род] не препятствовало выбору местоимения he или she, исходя из признака [одушевленность], и, наоборот, чтобы наличие [одушевленности] не мешало выбрать местоимение it, исходя из признака [средний род]. Ситуация, в действительности, значительно более запутана, чем мы здесь показали. Но дополнительные сложности не затрагивают общих принципов. Только что упомянутое предложение до сих пор (насколько мне известно) не было осуществлено в какой-либо из опубликованных работ. Но оно обладает несомненными достоинствами, и его осуществление, возможно, явится результатом тех достижений, которые наблюдаются в последнее время в «компонентной» семантике (см. § 10.5.1 и сл.). В то же время следует подчеркнуть не только то, что это предложение носит в настоящее время весьма умозрительный характер, но и что любая попытка его осуществить повлекла бы за собой довольно радикальный пересмотр тех способов формализации генеративной грамматики, которые были разработаны Хомским и его последователями. Другие авторы, склонные по иным причинам полагать, что такой пересмотр необходим, выдвинули за последнее время различные конкретные предложения; они будут упомянуты в примечаниях, прилагаемых к последним разделам этой книги. Однако в основной части книги мы будем следовать (быть может, за исключением частных вопросов) главной линии развития теории генеративной грамматики, как она была намечена Хомским и теми, кто с ним связан наиболее тесно. 4.3.5. РЕЗЮМЕ В этой главе мы ввели понятие «генеративной грамматики»; касаясь грамматических правил, мы намеренно упростили изложение, чтобы сосредоточиться на более общих принципах. Мы также поддерживали ту точку зрения, что предложения строятся посредством простой операции извлечения слов из словаря (в соответствии с их грамматической характеристикой) и сочетания их в последовательность. Кроме того, мы не проводили последовательного разграничения между «предложением» и «высказыванием», поскольку исходили из молчаливого предположения, что грамматика (дополненная фонологическими правилами и правилами фонетической интерпретации в терминах звуковой субстанции) порождает предложения, «тождественные» потенциальным высказываниям языка. Все эти моменты будут модифицированы в течение следующих двух глав. Прежде чем вернуться к дальнейшему рассмотрению генеративной модели, мы должны обсудить природу предложений и других грамматических единиц. |
|
||